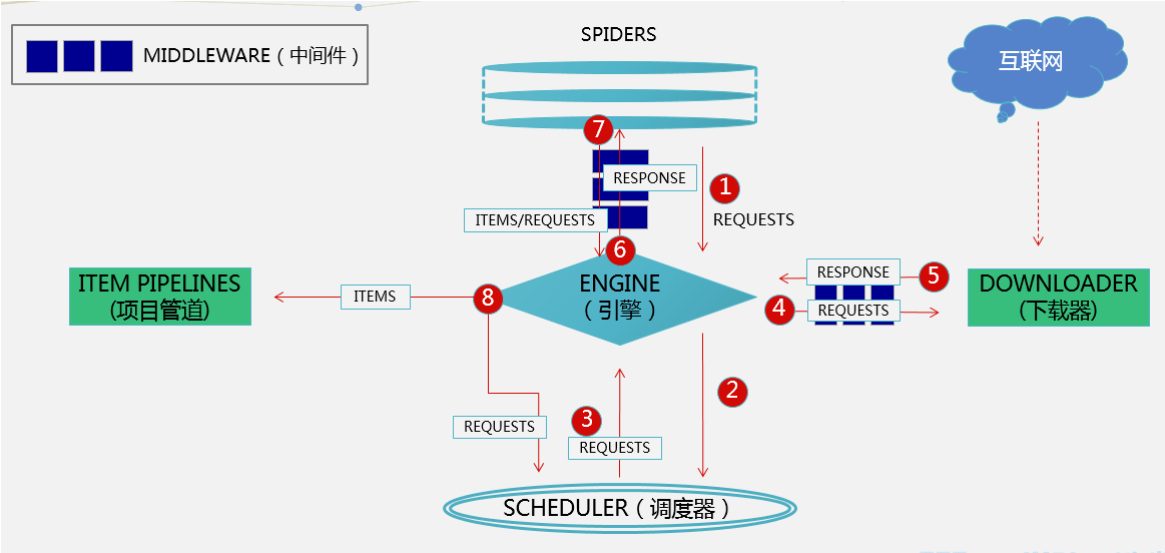
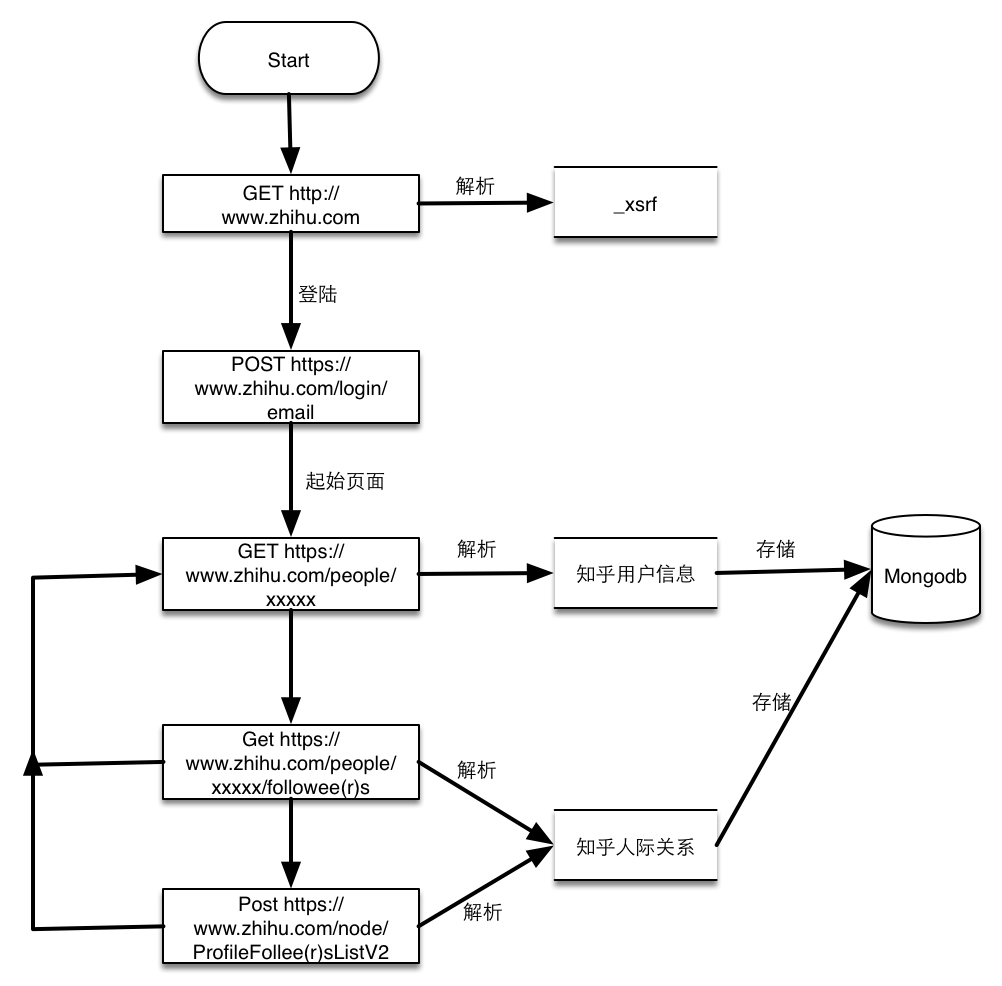
Scrapy 中 Request 对象和 Response 对象的各参数及属性介绍
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:31
各参数说明:
- 请求页面的url地址,bytes或str类型。
- 页面解析函数,Callback类型,Request请求对象的页面下载完成后,由该参数指定的页面解析函数解析页面,如果未传递该参数,默认调用Spider的parse方法。
- HTTP请求的方法,默认为‘GET’。
- HTTP请求的头部字典,dict 类型。
- HTTP请求的正文,bytes 或 str类型。
- Cookie信息字典,dict 类型。
- Request 的元数据字典,dict 类型,用于给框架中其他组件传递信息,比如中间件 Item Pipeline。其他组件可以使用Request 对象的 meta 属性访问该元数据字典 (request.meta), 也用于给响应处理函数传递信息。
- url 和 body 参数的编码默认为‘utf-8’。如果传入的url或body参数是str 类型,就使用该参数进行编码。
- 请求的优先级,默认值为0,优先级高的请求优先下载。
- 默认情况下(dont_filter=False),对同一个url地址多次提交下载请求,后面的请求会被去重过滤器过滤(避免重复下载)。如果将该参数置为True,可以使请求避免被过滤,强制下载。例如:在多次爬取一个内容随时间而变化的页面时(每次使用相同的url),可以将该参数设置为True。
- 请求出现异常或出现HTTP错误时(如404页面不存在)的回调函数。
- 上一篇: scrapydweb读取文本
- 下一篇: scrapy 知乎用户信息爬虫