
scrapy note
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:32
scrapy note
command
全局命令:
scrapy startproject myprojectscrapy fetch –nolog –headers http://www.example.com/scrapy view http://www.example.com/some/page.html项目(Project-only)命令:
–spider=SPIDER: 跳过自动检测spider并强制使用特定的spider
–a NAME=VALUE: 设置spider的参数(可能被重复)
–callback or -c: spider中用于解析返回(response)的回调函数
–pipelines: 在pipeline中处理item
–rules or -r: 使用 CrawlSpider 规则来发现用来解析返回(response)的回调函数
–noitems: 不显示爬取到的item
–nolinks: 不显示提取到的链接
–nocolour: 避免使用pygments对输出着色
–depth or -d: 指定跟进链接请求的层次数(默认: 1)
–verbose or -v: 显示每个请求的详细信息
scrapy parse http://www.example.com/ -c parse_itemscrapy genspider [-t template] <name> <domain>
scrapy genspider -t basic example example.com使用选择器(selectors)
body = ‘<html><body><span>good</span></body></html>’
Selector(text=body).xpath(‘//span/text()’).extract()
response = HtmlResponse(url=‘http://example.com', body=body)
Selector(response=response).xpath(’//span/text()‘).extract()Scrapy提供了两个实用的快捷方式: response.xpath() 及 response.css()
>>> response.xpath(’//base/@href‘).extract()
>>> response.css(’base::attr(href)‘).extract()
>>> response.xpath(’//a[contains(@href, “image”)]/@href‘).extract()
>>> response.css(’a[href=image]::attr(href)‘).extract()
>>> response.xpath(’//a[contains(@href, “image”)]/img/@src‘).extract()
>>> response.css(’a[href=image] img::attr(src)‘).extract()嵌套选择器(selectors)
选择器方法( .xpath() or .css() )返回相同类型的选择器列表,因此你也可以对这些选择器调用选择器方法。下面是一个例子:
links = response.xpath(’//a[contains(@href, “image”)]‘)
for index, link in enumerate(links):
args = (index, link.xpath('@href').extract(), link.xpath('img/@src').extract())<br/>
print 'Link number %d points to url %s and image %s' % args</code></pre>
结合正则表达式使用选择器(selectors)
Selector 也有一个 .re() 方法,用来通过正则表达式来提取数据。然而,不同于使用 .xpath() 或者 .css() 方法, .re() 方法返回unicode字符串的列表。所以你无法构造嵌套式的 .re() 调用。
>>> response.xpath(’//a[contains(@href, “image”)]/text()‘).re(r’Name:\s(.)‘)
使用相对XPaths
>>> for p in divs.xpath(’//p‘): # this is wrong - gets all <p> from the whole document
… print p.extract()
>>> for p in divs.xpath(’.//p‘): # extracts all <p> inside
… print p.extract()
>>> for p in divs.xpath(’p‘): #gets all <p> from the whole document
… print p.extract()
例如在XPath的 starts-with() 或 contains() 无法满足需求时, test() 函数可以非常有用。
>>> sel.xpath(’//li//@href‘).extract()
>>> sel.xpath(’//li[re:test(@class, “item-\d$”)]//@href‘).extract()
XPATH TIPS
- Avoid using contains(.//text(), ‘search text’) in your XPath conditions. Use contains(., ‘search text’) instead.
- Beware of the difference between //node[1] and (//node)[1]
- When selecting by class, be as specific as necessary,When querying by class, consider using CSS
- Learn to use all the different axes
- Useful trick to get text content
Item Loaders
populate items
def parse(self, response):
l = ItemLoader(item=Product(), response=response)<br/>
l.add_xpath('name', '//div[@class="product_name"]')<br/>
l.add_xpath('name', '//div[@class="product_title"]')<br/>
l.add_xpath('price', '//p[@id="price"]')<br/>
l.add_css('stock', 'p#stock]')<br/>
l.add_value('last_updated', 'today') # you can also use literal values<br/>
return l.load_item()</code></pre>
Item Pipeline
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
编写你自己的item pipeline
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:
- item (Item 对象) – 被爬取的item
- spider (Spider 对象) – 爬取该item的spider
Write items to MongoDB
import pymongo
class MongoPipeline(object):
def init(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri<br/>
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):<br/>
return cls(<br/>
mongo_uri=crawler.settings.get('MONGO_URI'),<br/>
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')<br/>
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)<br/>
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
collection_name = item.__class__.__name__<br/>
self.db[collection_name].insert(dict(item))<br/>
return item</code></pre>
为了启用一个Item Pipeline组件,你必须将它的类添加到 ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,<br/>
'myproject.pipelines.JsonWriterPipeline': 800,<br/>
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
实践经验
同一进程运行多个spider
from twisted.internet import reactor, defer
from scrapy.crawler import CrawlerRunner
from scrapy.utils.project import get_project_settings
runner = CrawlerRunner(get_project_settings())
dfs = set()
for domain in [’scrapinghub.com‘, ’insophia.com‘]:
d = runner.crawl('followall', domain=domain)<br/>
dfs.add(d)
defer.DeferredList(dfs).addBoth(lambda _: reactor.stop())
reactor.run() # the script will block here until all crawling jobs are finished
避免被禁止(ban)
- 使用user agent池,轮流选择之一来作为user agent。池中包含常见的浏览器的user agent(google一下一大堆)
- 禁止cookies(参考 COOKIES_ENABLED),有些站点会使用cookies来发现爬虫的轨迹。
- 设置下载延迟(2或更高)。参考 DOWNLOAD_DELAY 设置。
- 如果可行,使用 Google cache 来爬取数据,而不是直接访问站点。
- 使用IP池。例如免费的 Tor项目 或付费服务(ProxyMesh)。
- 使用高度分布式的下载器(downloader)来绕过禁止(ban),您就只需要专注分析处理页面。这样的例子有: Crawlera
- 增加并发 CONCURRENT_REQUESTS = 100
- 禁止cookies:COOKIES_ENABLED = False
- 禁止重试:RETRY_ENABLED = False
- 减小下载超时:DOWNLOAD_TIMEOUT = 15
- 禁止重定向:REDIRECT_ENABLED = False
- 启用 “Ajax Crawlable Pages” 爬取:AJAXCRAWL_ENABLED = True
对爬取有帮助的实用Firefox插件
- Firebug
- XPather
- XPath Checker
- Tamper Data
- Firecookie
- 自动限速:AUTOTHROTTLE_ENABLED=True
other
- 上一篇: scrapy 知乎用户信息爬虫
- 下一篇: scp命令 配置信任关系
相关文章
-
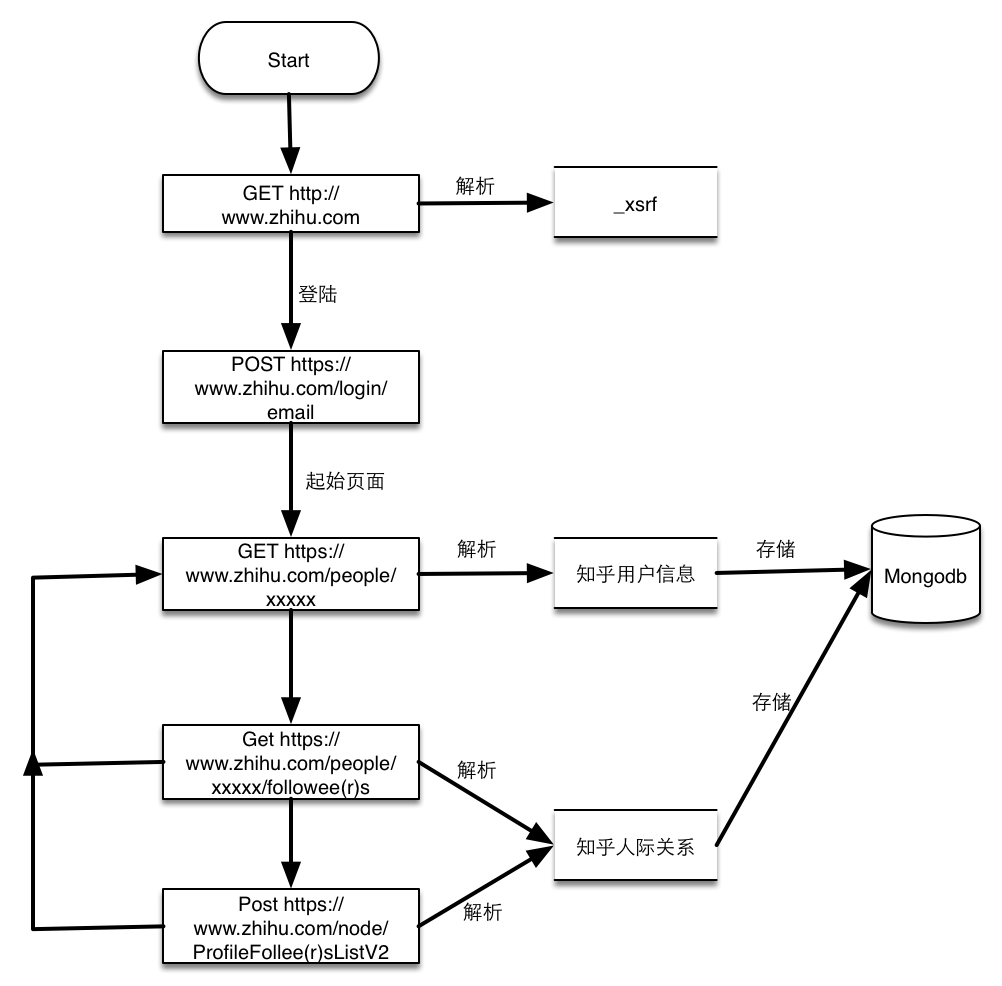
scrapy 知乎用户信息爬虫
scrapy 知乎用户信息爬虫
- 互联网
- 2026年06月03日
-
Scrapy 中 Request 对象和 Response 对象的各参数及属性介绍
Scrapy 中 Request 对象和 Response 对象的各参数及属性介绍
- 互联网
- 2026年06月03日
-
scrapydweb读取文本
scrapydweb读取文本
- 互联网
- 2026年06月03日
-
scp命令 配置信任关系
scp命令 配置信任关系
- 互联网
- 2026年06月03日
-
scanf同时为多个变量赋值
scanf同时为多个变量赋值
- 互联网
- 2026年06月03日
-

scan design flow(二)
scan design flow(二)
- 互联网
- 2026年06月03日



