
Scrapy爬虫大战京东商城
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:31
def parse_url(self,response):
if response.status==200: #判断是否请求成功<br/>
# print response.url<br/>
pids = set() #这个集合用于过滤和保存得到的id,用于作为后面的ajax请求的url构成<br/>
try:<br/>
all_goods = response.xpath("//div[@id='J_goodsList']/ul/li") #首先得到所有衣服的整个框架,然后从中抽取每一个框架
for goods in all_goods: #从中解析每一个
# scrapy.shell.inspect_response(response,self) #这是一个调试的方法,这里会直接打开调试模式<br/>
items = JdSpiderItem() #定义要抓取的数据<br/>
img_url_src = goods.xpath("div/div[1]/a/img/@src").extract() # 如果不存在就是一个空数组[],因此不能在这里取[0]<br/>
img_url_delay = goods.xpath(<br/>
"div/div[1]/a/img/@data-lazy-img").extract() # 这个是没有加载出来的图片,这里不能写上数组取第一个[0]<br/>
price = goods.xpath("div/div[3]/strong/i/text()").extract() #价格<br/>
cloths_name = goods.xpath("div/div[4]/a/em/text()").extract()<br/>
shop_id = goods.xpath("div/div[7]/@ data-shopid").extract()<br/>
cloths_url = goods.xpath("div/div[1]/a/@href").extract()<br/>
person_number = goods.xpath("div/div[5]/strong/a/text()").extract()<br/>
pid = goods.xpath("@data-pid").extract()<br/>
# product_id=goods.xpath("@data-sku").extract()<br/>
if pid:<br/>
pids.add(pid[0])<br/>
if img_url_src: # 如果img_url_src存在<br/>
print img_url_src[0]<br/>
items['img_url'] = img_url_src[0]<br/>
if img_url_delay: # 如果到了没有加载完成的图片,就取这个url<br/>
print img_url_delay[0]<br/>
items['img_url'] = img_url_delay[0] # 这里如果数组不是空的,就能写了<br/>
if price:<br/>
items['price'] = price[0]<br/>
if cloths_name:<br/>
items['cloths_name'] = cloths_name[0]<br/>
if shop_id:<br/>
items['shop_id'] = shop_id[0]<br/>
shop_url = "https://mall.jd.com/index-" + str(shop_id[0]) + ".html"<br/>
items['shop_url'] = shop_url<br/>
if cloths_url:<br/>
items['cloths_url'] = cloths_url[0]<br/>
if person_number:<br/>
items['person_number'] = person_number[0]<br/>
# if product_id:<br/>
# print "************************************csdjkvjfskvnk***********************"<br/>
# print self.comments_url.format(str(product_id[0]),str(self.count))<br/>
# yield scrapy.Request(url=self.comments_url.format(str(product_id[0]),str(self.count)),callback=self.comments)<br/>
#yield scrapy.Request写在这里就是每解析一个键裤子就会调用回调函数一次<br/>
yield items<br/>
except Exception:<br/>
print "********************************************ERROR**********************************************************************"
yield scrapy.Request(url=self.search_url.format(str(response.meta[‘search_page’]),“,”.join(pids)),callback=self.next_half_parse) #再次请求,这里是请求ajax加载的数据,必须放在这里,因为只有等到得到所有的pid才能构成这个请求,回调函数用于下面的解析
- 上一篇: Scrapy爬虫框架补充内容一(Linux环境)
- 下一篇: scrapydweb读取文本
相关文章
-
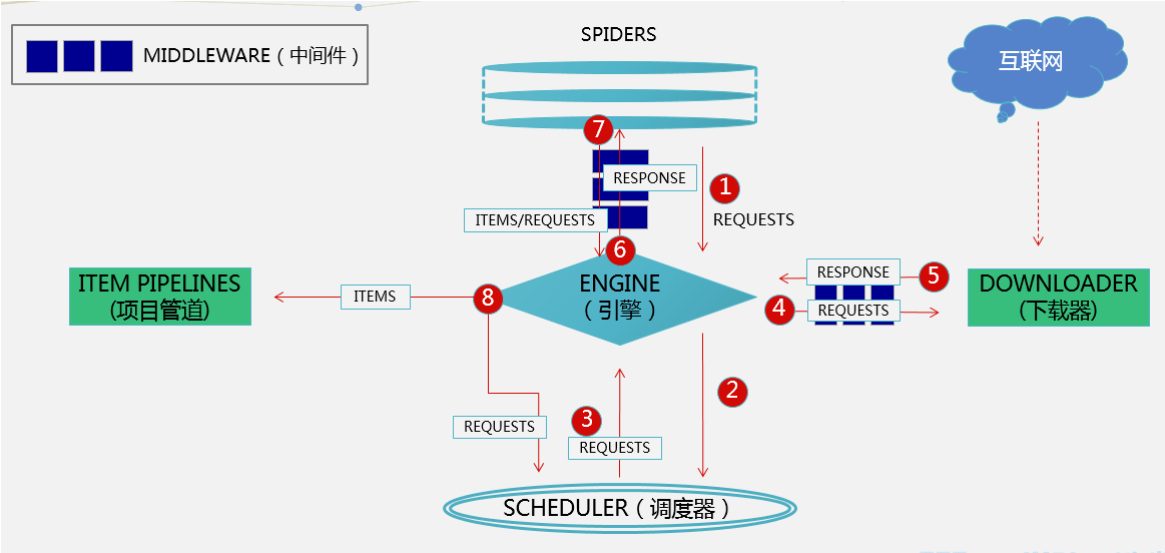
Scrapy爬虫框架补充内容一(Linux环境)
Scrapy爬虫框架补充内容一(Linux环境)
- 互联网
- 2026年06月03日
-
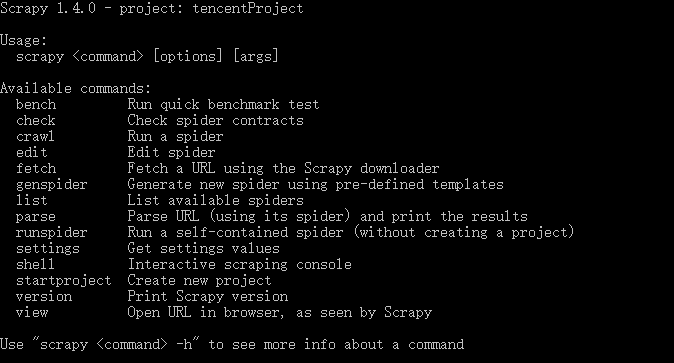
Scrapy爬虫框架的学习
Scrapy爬虫框架的学习
- 互联网
- 2026年06月03日
-
Scrapy爬虫实例——校花网
Scrapy爬虫实例——校花网
- 互联网
- 2026年06月03日
-
scrapydweb读取文本
scrapydweb读取文本
- 互联网
- 2026年06月03日
-
Scrapy 中 Request 对象和 Response 对象的各参数及属性介绍
Scrapy 中 Request 对象和 Response 对象的各参数及属性介绍
- 互联网
- 2026年06月03日
-
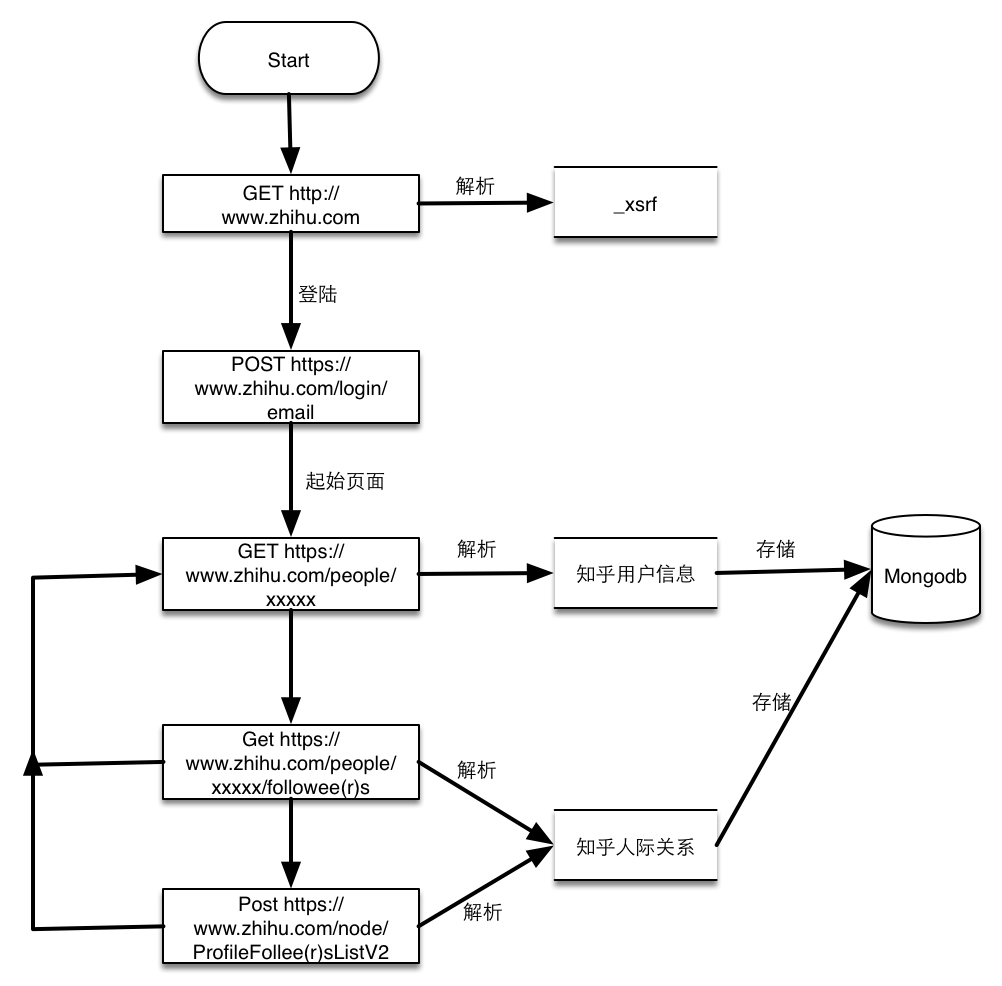
scrapy 知乎用户信息爬虫
scrapy 知乎用户信息爬虫
- 互联网
- 2026年06月03日



