
Scrapy爬虫框架的学习
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:31
第一步安装
首先得安装它,我使用的pip安装的
因为我电脑上面安装了两个python,一个是python2.x,一个是python3.x,所以为了区分,所以,在cmd中,我就使用命令:python2 -m pip install Scrapy (注意我这里使用python2的原因是我给2个python重命名了一下)
安装之后,输入scrapy,出现如下图这样子的信息,表示成功安装了
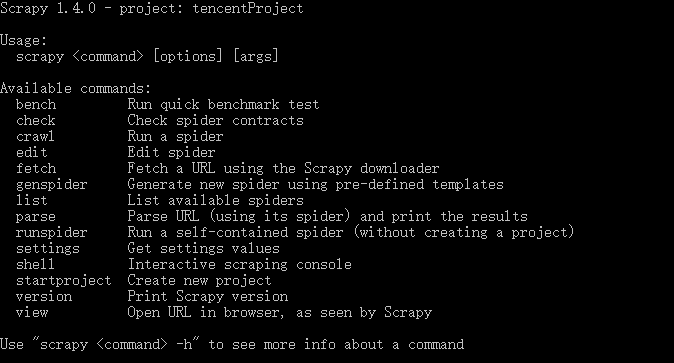
如果有错误,可以参考一下:http://www.cnblogs.com/angelgril/p/7511741.html ,有可能会有用
第二步新建项目
通过命令scrapy startproject xxx 来创建scrapy项目 (注意:你在哪个文件夹下面使用这个命令,项目就创建在哪个文件夹下面,你可以cd到某个你特定的文件夹下面,在使用该命令创建项目)
创建完后,用pycharm编辑器打开项目
项目结构如下图:

下面来简单介绍一下各个文件的作用:
scrapy.cfg :项目的配置文件
tencentProject/ :项目的Python模块,将会从这里引用代码
tencentProject/items.py :项目的items文件
tencentProject/pipelines.py :项目的pipelines文件
tencentProject/settings.py :项目的设置文件
tencentProject/spiders/ :存储爬虫的目录
scrapy 爬虫网站 一共需要4步:
新建项目 (Project):新建一个新的爬虫项目
明确目标 (Items):明确你想要抓取的目标
制作爬虫 (Spider):制作爬虫开始爬取网页
存储内容 (Pipeline):设计管道存储爬取内容
第三步明确目标
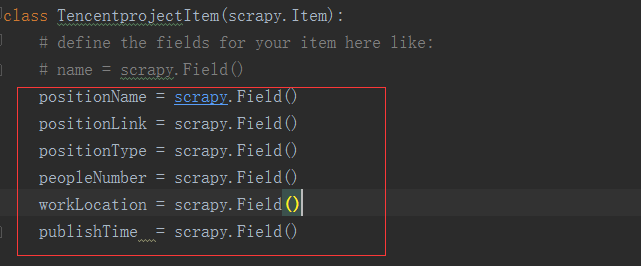
修改 tencentProject目录下的 items.py 文件,添加相应的属性,(注意:scrapy.Field(),是固定的,只要记住就行了)
刚开始看起来可能会有些看不懂,但是定义这些item能让你用其他组件的时候知道你的items到底是什么。可以把Item简单的理解成封装好的类对象
第四步制作爬虫
1、爬取
要建立一个Spider, 你必须用scrapy.spider.BaseSpider创建一个子类 ,并确定 三 个强制的属性:
name :爬虫的识别名称,必须是唯一的,在不同的爬虫中你必须定义不同的名字。
start_urls :爬取的URL列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会
从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse() :解析的方法,调用的时候传入从每一个URL传回的Response对象作为唯一参
数,负责解析并匹配抓取的数据(解析为item),跟踪更多的URL
可选设置的参数allow_domains 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页。
在Scrapy里,使用一种叫做 XPath selectors 的机制,它基于 XPath 表达式,

下面我们来定义一只爬虫,命名为 tencent.py ,保存在 tencentProject\spiders 目录下。
tencent.py代码如下:
注意:里面的关键字yield 的作用是:返回数据后,还能继续去执行未完成的操作,它不像return,但是,它又有return的返回数据的功能
2、存储
在管道文件pipelines.py 去添加一下代码:
- 上一篇: Scrapy爬虫实例——校花网
- 下一篇: Scrapy爬虫框架补充内容一(Linux环境)
相关文章
-
Scrapy爬虫实例——校花网
Scrapy爬虫实例——校花网
- 互联网
- 2026年06月03日
-
Scrapy数据解析和持久化
Scrapy数据解析和持久化
- 互联网
- 2026年06月03日
-
scrapy之Request对象
scrapy之Request对象
- 互联网
- 2026年06月03日
-
Scrapy爬虫框架补充内容一(Linux环境)
Scrapy爬虫框架补充内容一(Linux环境)
- 互联网
- 2026年06月03日
-
Scrapy爬虫大战京东商城
Scrapy爬虫大战京东商城
- 互联网
- 2026年06月03日
-
scrapydweb读取文本
scrapydweb读取文本
- 互联网
- 2026年06月03日



