5 种排行榜实现方案:从简单到复杂的实现方案!
- 作者: 五速梦信息网
- 时间: 2026年06月19日 04:38
userScores; public void open(Configuration parameters) {
MapStateDescriptor descriptor =
new MapStateDescriptor<>("userScores", String.class, Double.class);
userScores = getRuntimeContext().getMapState(descriptor);
}
public void processElement(UserAction action, Context ctx, Collector> out) {
double newScore = userScores.getOrDefault(action.getUserId(), 0.0) + calculateScore(action);
userScores.put(action.getUserId(), newScore);
out.collect(new Tuple2<>(action.getUserId(), newScore));
}
});
scores.keyBy(0)
.process(new RankProcessFunction())
.addSink(new RankingSink());
”` 优点:
真正的实时更新
可处理超高并发
支持复杂计算逻辑 缺点:
架构复杂度高
运维成本高
需要专业团队维护 架构图如下:
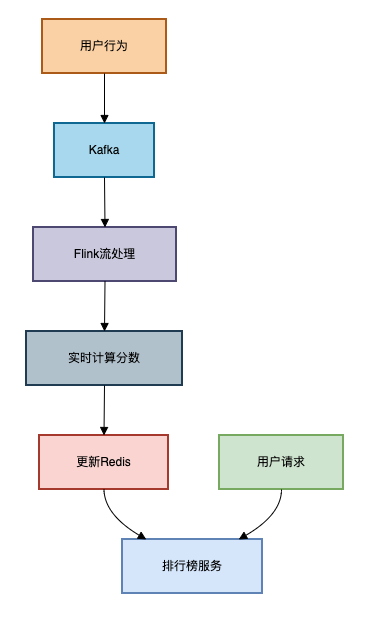
方案对比与选择
方案 数据量 实时性 复杂度 适用场景 数据库排序 小 低 低 个人项目、小规模应用 缓存+定时任务 中 中 中 中小型应用,可接受延迟 Redis有序集合 大 高 中 大型应用,需要实时更新 分片+Redis集群 超大 高 高 超大型应用,超高并发 预计算+分层缓存 大 中高 高 读多写少,访问量极大 实时计算+流处理 超大 实时 极高 社交平台,需要实时排名 总结
在选择排行榜实现方案时,我们需要综合考虑以下几个因素:
- 数据规模:数据量大小直接决定了我们选择哪种方案
- 实时性要求:是否需要秒级更新,还是分钟级甚至小时级都可以接受
- 并发量:系统的预期访问量是多少
- 开发资源:团队是否有足够的技术能力维护复杂方案
- 业务需求:排行榜的计算逻辑是否复杂 对于大多数中小型应用,方案二(缓存+定时任务)或方案三(Redis有序集合)已经足够。如 果业务增长迅速,可以逐步演进到方案四(分片+Redis集群)。 而对于社交平台等需要实时更新的场景,则需要考虑方案五(预计算+分层缓存)或方案六(实时计算+流处理),但要做好技术储备和架构设计。 最后,无论选择哪种方案,都要做好监控和性能测试。排行榜作为高频访问的功能,其性能直接影响用户体验。 建议在实际环境中进行压测,根据测试结果调整方案。 希望这六种方案的详细解析能帮助大家在工作中做出更合适的选择。 > 记住,没有最好的方案,只有最适合的方案。
相关文章
-

3款基于.NET开源且免费的远程桌面工具分享
3款基于.NET开源且免费的远程桌面工具分享
- 互联网
- 2026年06月19日
-
3斤是多少两 生活常识(3斤4两等于多少克)
3斤是多少两 生活常识(3斤4两等于多少克)
- 互联网
- 2026年06月19日
-
3.长相年轻的女人,有自己生活的底气,有选择生活的能力
3.长相年轻的女人,有自己生活的底气,有选择生活的能力
- 互联网
- 2026年06月19日
-
5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
5. RabbitMQ 消息队列中 Exchanges(交换机) 的详细说明
- 互联网
- 2026年06月19日
-
5s怎么设置铃声(教你如何制作设置iPhone5铃声)
5s怎么设置铃声(教你如何制作设置iPhone5铃声)
- 互联网
- 2026年06月19日
-
8月是夏天还是秋天(9月是夏天还是秋天)
8月是夏天还是秋天(9月是夏天还是秋天)
- 互联网
- 2026年06月19日