
端是什么编码
- 作者: 五速梦信息网
- 时间: 2026年06月03日 14:02
端是什么编码
- 2024-08-27
借助一些模块来转换,比如,html-entities Github var Entities = require('html-entities').XmlEntities; entities = new Entities(); var str = '<p> 虽然可以在网上搜索很多的这样类似的插件,但是就是因为太多了而不知道该怎么选择,所以请大家啊推荐一下,好用的,而且还在积极维护的触屏插件 </p>'; console.log(entities.decode(str)); //ou
转自:http://blog.sina.com.cn/s/blog_87cb63e50102w2b6.html 以下为正文: *************************************************** 基本概念 有信息交换就会产生编码.传输.解码三个过程.编码是信息从一种形式转变成另一种形式的过程,正如人类的语言通过声带编码,转换成声波.解码是编码的逆函数,耳膜接收声波,通过脑神经解码成人类文化所能理解的信息. 字符集是一种文化上下文下的所有文字符号集合,它的作用是规
经常可能出现查询Oracle数据时,中文显示乱码,这很可能是因为,Oracle服务端的字符编码与客户端不一致引起的. 这时,我们需要做的是,如何设置自己的客户端字符编码与服务端一致. 查询Oracle服务端字符编码 --AMERICAN_AMERICA.ZHS16GBK select userenv('language') from dual; 这时,可以通过以下命令临时设置本次命令行模式使用其字符编码: set nls_lang=AMERICAN_AMERICA.ZHS16GBK 当然也可以通
(2012-10-30 21:38:33) 转载▼ 标签: 杂谈 分类: ORACLE 导出sql文件出现乱码问题,百度之后,发现问题是由于PL/SQL客户端和ORACLE的字符编码设置不一致引起的.(之前在登录PLSQL/Developer的时候有过提示,但是没在意),网上资料如下: 登录PLSQL/Developer是提示 客户端和服务端的字符编码设置不一致导致的.上网 得知oralce字符编码设置和查询的一些方法,记录如下: 1. NLS_LANG 参数组成NLS_LANG参数由以下部分组
编码.解码技术是我们在程序中开发中经常使用到的,对一些敏感信息的存储,比如密码之类的,我们一般是不会直接以明文直接存储到数据库的,而是会通过各种算法,可以是现成的MD5(一种散列算法).或者是Hash算法+Salt(混淆因子),甚至是自己定义的一套算法进行加解密.这里不想阐述加解密技术,在之前的一篇博客当中,简单列举了两种基本方法,见.NET加解密技术.这里重点讲解一下编码.解码以及乱码的相关问题. 我们先看一个简单的例子: string str = "abcd";//测试字符串 by
乱码的出现是因为编码与解码的不一致造成的,假如你对“中文”两个字进行了gbk格式的保存,却用utf-8格式的解读,是肯定会出现乱码的. 如何避免中文乱码:应用上下统一用一种编码格式. utf-8或者gbk 建议用utf-8. 虽然占空间,但是通用性强,它属于国际编码格式.相反,gbk是国家级的. 下面简单说下以tomcat为容器的程序响应response的编码流程: .java--.class .jsp--.java--.class~~.html .js--.js .css--.css 编码涉
http://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/ 几种常见的编码格式 为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言.由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元-- byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解.我们可以把计算
UTF-16编码方式 1. UTF-16编码方式源于UCS-2(Universal Character Set coded in 2 octets.2-byte Universal Character Set).而UCS-2,是早期遗留下来的历史产物. UCS-2将字符编号(即码点值)直接映射为字符编码(CEF,而非CES,详见前文中对现代字符编码模型的解释),亦即字符编号就是字符编码,中间没有经过特别的编码算法转换.因此,从现代字符编码模型的角度来看的话,此时并没有将编号字符集CCS与字符编码
任务一:团队项目<软件设计方案说明书>Github链接:https://github.com/Sophur/Team-Project 任务二:项目集成开发环境: (1)JSP技术 JSP(Java server page)页面由HTML代码和嵌入其中的Java代码所组成.Java servlet 是JSP的技术基础,而且大型的Web应用程序的开发需要Java servlet和JSP配合才能完成.JSP具备了Java技术的简单易用,完全的面向对象,具有平台无关性且安全可靠,主要面向因特网的所有特
几种常见的编码格式 为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言.由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元—— byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解.我们可以把计算机能够理解的语言假定为英语,其它语言要能够在计算机中使用必须经过一次翻译,把它翻译成英语.这个翻译的过程就是编码.所以可以想
编码(util/coding.h util/coding.cc) LevelDB将整型编码为二进制字符串的形式,同时又能够和ASCII字符区分. 首先是定长编码: void EncodeFixed32(char *buf, uint32_t value) { if (port::kLittleEndian) { memcpy(buf, &value, sizeof(value)); } else { buf[0] = value & 0xff; buf[1] = (value >&g
Netty简介Netty是一个基于JAVA NIO 类库的异步通信框架,它的架构特点是:异步非阻塞.基于事件驱动.高性能.高可靠性和高可定制性.换句话说,Netty是一个NIO框架,使用它可以简单快速地开发网络应用程序,比如客户端和服务端的协议.Netty大大简化了网络程序的开发过程比如TCP和UDP的 Socket的开发.Netty 已逐渐成为 Java NIO 编程的首选框架. 什么是物联网?nio通信框架 物联网主要运用到netty哪些特性a.TCP长连接b.能够和各种序列化框架完美整合
前几天有个朋友,说他们公司做手游,服务端用的DIOCP3里面做文件服务器,客户端用cocos-x,在调试与diocp通信时老是失败! 于是,我下载了一个Codeblocks经过几个小时的折腾,终于折腾出来了,把其中的一些心酸记录下,以便以后查阅. 1.windows下面使用socket的一些函数时,需要设置工程的选项或者工具的编译选项 [project –> build options]->[linker settings]或者[setting]->[complier]->Link
MySQL数据库初识 MySQL数据库 本节目录 一 数据库概述 二 MySQL介绍 三 MySQL的下载安装.简单应用及目录介绍 四 root用户密码设置及忘记密码的解决方案 五 修改字符集编码 六 初识sql语句 一 数据库概述 1. 数据库??? 什么是数据库呢? 先来看看百度怎么说的 数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增.截取.更新.删除等操作. 所谓“数据库”系以一定方式储存在一起.能予多个用户共享.具有尽可能小的冗余度.与应用程序
在网上已经转悠好几天了, 这篇文章让我知道了UTF-16的前世今生, 感谢作者https://cloud.tencent.com/developer/article/1384687 1. UTF-16编码方式源于UCS-2(Universal Character Set coded in 2 octets.2-byte Universal Character Set).而UCS-2,是早期遗留下来的历史产物. UCS-2将字符编号直接映射为字符编码(CEF,而非CES,详见前文中对现代字符编码模
摘自:http://www.cnblogs.com/yaya-yaya/p/5768616.html 红色 主要点 灰色 内容 绿色 知识点 橘色 补充内容 几种常见的编码格式 为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言.由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元—— byte 来表示,因而必须要
为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言.由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元—— byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能理解.我们可以把计算机能够理解的语言假定为英语,其它语言要能够在计算机中使用必须经过一次翻译,把它翻译成英语.这个翻译的过程就是编码.所以可以想象只要不是说英语的国
数据库编程的编码问题数据库编程设计的编码问题包括三个方面: 数据库服务器编码: 数据库客户端编码: 本地环境编码.(1)数据库服务器字符编码:数据库服务器支持某种编码,是指数据库服务器能够从客户端接收.存储以及向客户端提供该种编码的字符,并能将该种编码的字符转换到其它编码.查看PostgreSQL数据库服务器端编码:postgres=# show server_encoding; server_encoding ----------------- UTF8postgres=#
哈夫曼树介绍 哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树.所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数).树的带权路径长度记为WPL=(W1*L1+W2*L2+W3*L3+...+ Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n).可以证明哈夫曼树的WPL是最小的. 利用哈夫曼编码进行通信可以大大提高信道利用率
转载:http://blog.csdn.net/peach99999/article/details/7231247 深入讨论java乱码问题 几种常见的编码格式 为什么要编码 不知道大家有没有想过一个问题,那就是为什么要编码?我们能不能不编码?要回答这个问题必须要回到计算机是如何表示我们人类能够理解的符号的,这些符号也就是我们人类使用的语言.由于人类的语言有太多,因而表示这些语言的符号太多,无法用计算机中一个基本的存储单元—— byte 来表示,因而必须要经过拆分或一些翻译工作,才能让计算机能
1.此时服务器端接收到客户端提交来的post请求 2.request.getParameter("name")方法开始从请求中解析数据 并使用默认的编码 格式进行编码(ISO-88559) 3因为发送端与接收端编码不一样 出现乱码现象的主要原因是 request.getParameter的默认编码有问题
热门专题
相关文章
-

(30)auth模块(django自带的用户认证模块)
(30)auth模块(django自带的用户认证模块)
- 互联网
- 2026年06月03日
-
(C#)Windows Shell 外壳编程系列7
(C#)Windows Shell 外壳编程系列7
- 互联网
- 2026年06月03日
-
(C语言)格式输出,右对齐
(C语言)格式输出,右对齐
- 互联网
- 2026年06月03日
-

!!Python字典增删操作技巧简述+Python字典嵌套字典与排序
!!Python字典增删操作技巧简述+Python字典嵌套字典与排序
- 互联网
- 2026年06月03日
-
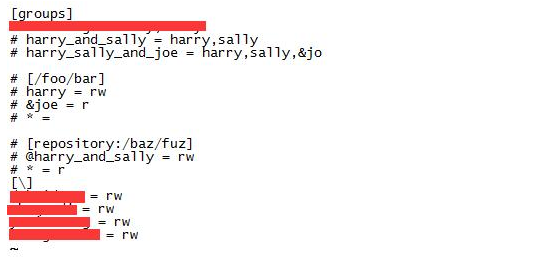
Linux下的SVN服务器搭建
Linux下的SVN服务器搭建
- 互联网
- 2026年06月03日
-
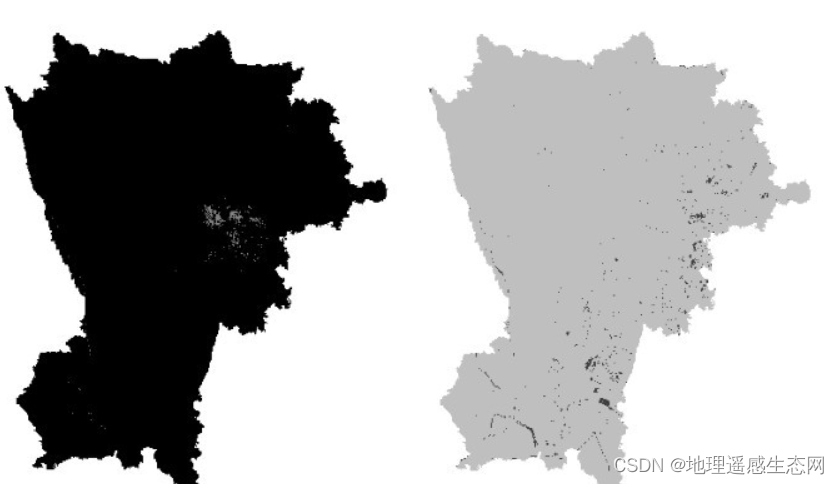
ARCGIS API for Python进行城市区域提取
ARCGIS API for Python进行城市区域提取
- 互联网
- 2026年06月03日







