使用libdivide加速整数除法运算
- 作者: 五速梦信息网
- 时间: 2026年06月19日 04:51
fast_d(23);
for (auto _ : stat) { for (auto n : v) {
benchmark::DoNotOptimize(n/=fast_d); }
}
}
BENCHMARK(bench_libdiv_const);
BENCHMARK_MAIN();
“
测试内容是连续除十个随机生成的被除数,现代cpu性能还是很强悍的,如果只测除一次的情况,那么会得到一堆0.X纳秒的结果,那样对比不够明显,也容易引入统计误差和噪音。
测试运行也分两部分,一是使用-O2优化级别进行测试,在这个级别下编译器会采用比较保守的优化策略,并且只应用少量的SIMD指令;另一个是用-O3 -march=native进行优化,在这个级别下编译器会最大限度优化程序性能并且尽可能利用当前cpu上所有可用的指令(包括SIMD)进行优化。
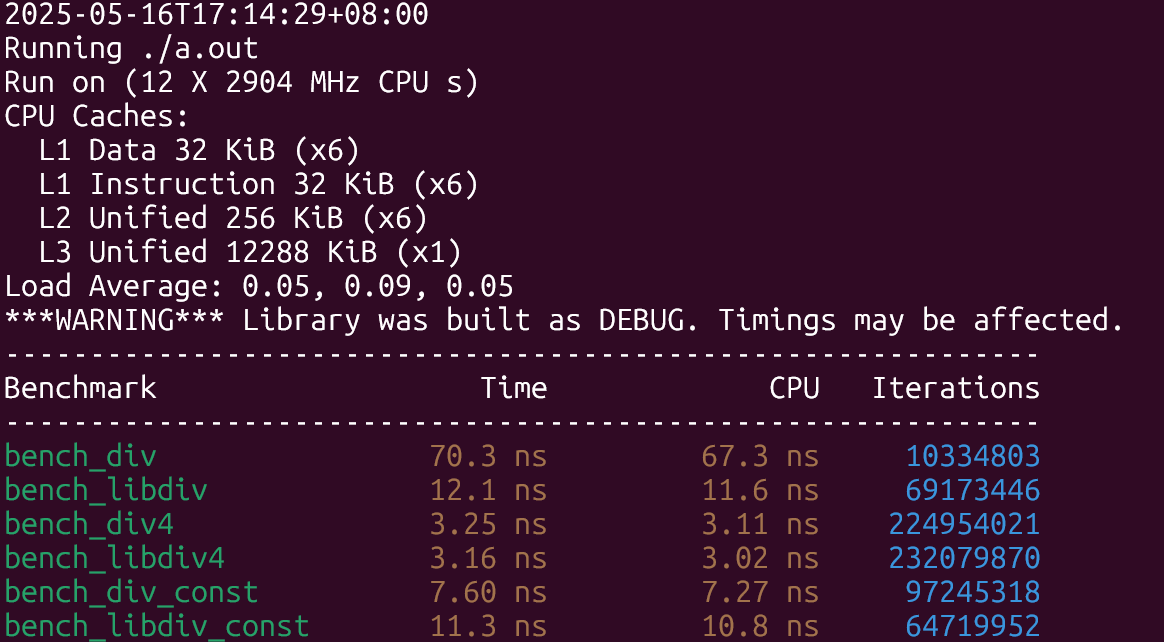
先来看看老机器上(10代i5台式机)的结果:
下面是开启native之后的结果:
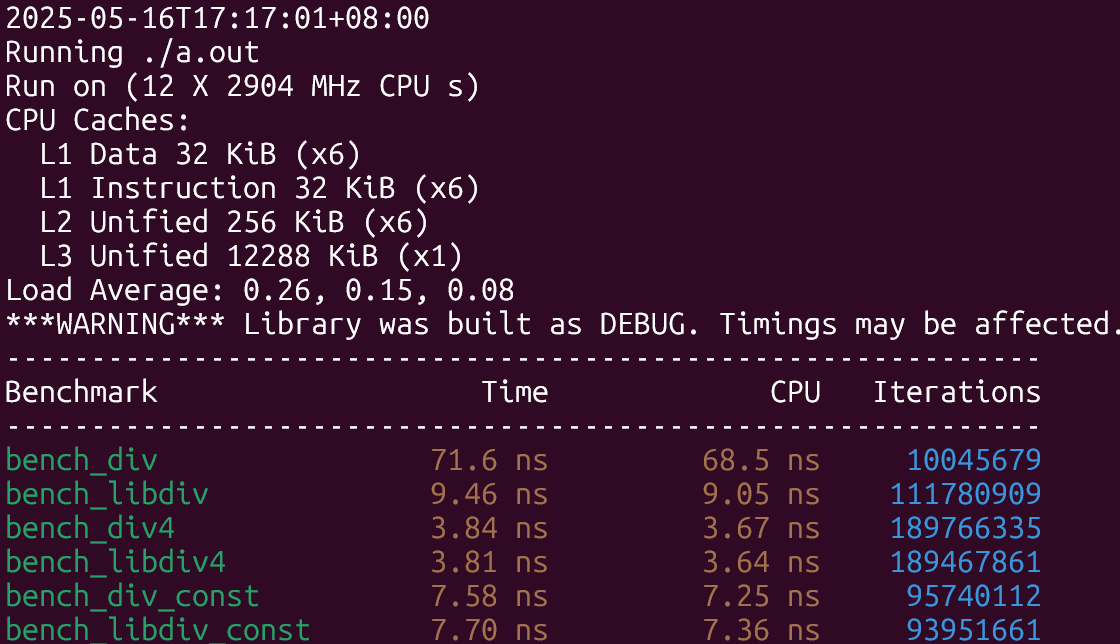
结果符合预期,在除数未知的情形下libdivide性能提升了8倍左右,除数已知且是2的幂的时候两者差不多,只有第三种情形下libdivide稍慢与直接除,原因大概是因为编译器也做了和libdivide类似的优化,但libdivide还需要额外探测除数的性质以及需要多几次函数调用,因此性能上稍慢了一些。
最大化利用SIMD结果类似,情形3下的差距缩小了很多。
然后我们看看在更新的机器上的表现(14代i7):
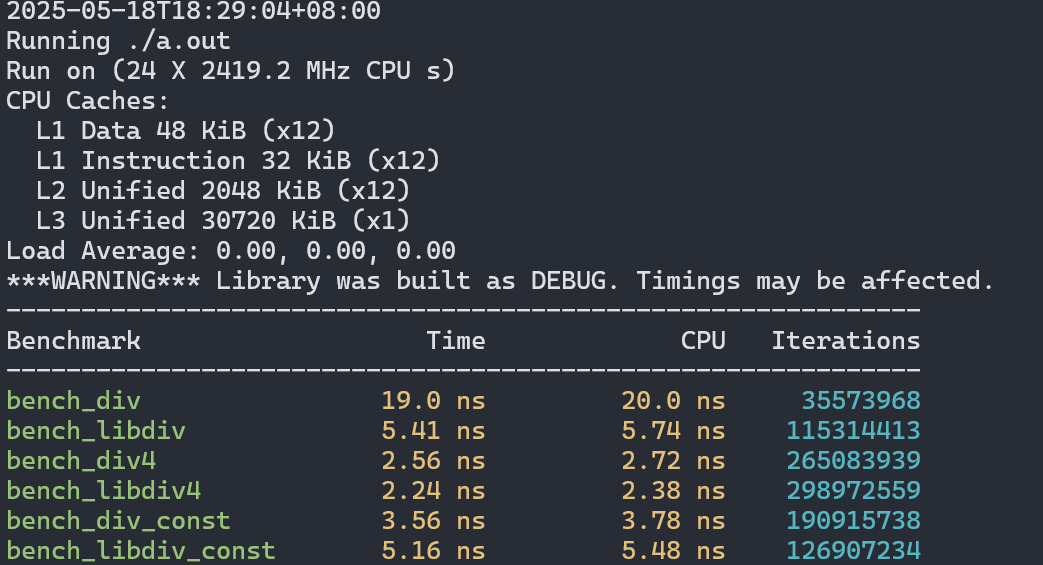
不启用最高级别优化时结果与老机器类似,但性能差距缩小了。
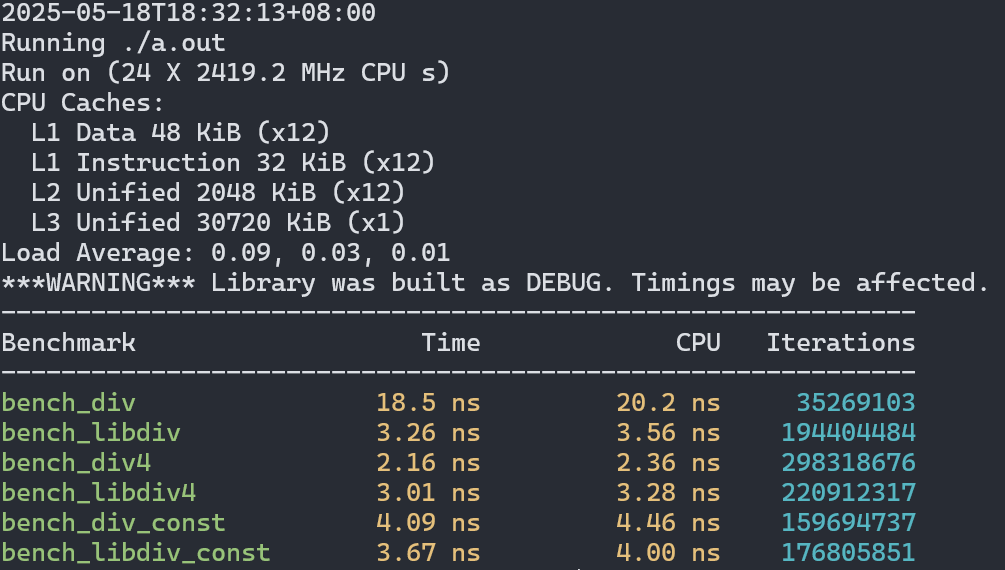
最大程度利用SIMD后现在情形3变快,但场景2又稍显落后了。在场景1中的提升也只有5倍左右。
总体来说在libdivide`宣称的场景下,性能提升确实很可观,但还没到1个数量级这么夸张,不过我的测试环境都没有avx512支持,对于支持这个指令集的cpu来说也许性能还能再提升一些最终达到文档里说的10倍。在其他场景下libdivide的优势并不明显,所以追求极致性能的时候不是很建议在非场景1的情况下使用这个库。
总结
如果整数除法成为了性能瓶颈的话,可以尝试使用libdivide。这里总结下优缺点。
优点:
- 使用方便,只需要导入头文件
- 在除数未知的情况下能获得显著的性能提升
- 能利用SIMD,充分释放现代cpu性能 缺点:
- 只适用于除数未知的情况下
- 且除数要固定,因为频繁创建销毁
libdivide::divider对象要付出额外的代价,会导致优化效果打折甚至负优化 libdivide::divider对象比整数要多占用一个字节,尽管这个对象是栈分配的,但对空间消耗比较敏感的程序可能需要谨慎使用,尤其是账面是虽然只多一字节,但遇到需要内存对齐的时候可能占用就要翻倍了。 总得来说libdivide还是很值得一试的库,但任何优化都要有性能测试做依据。
相关文章
-
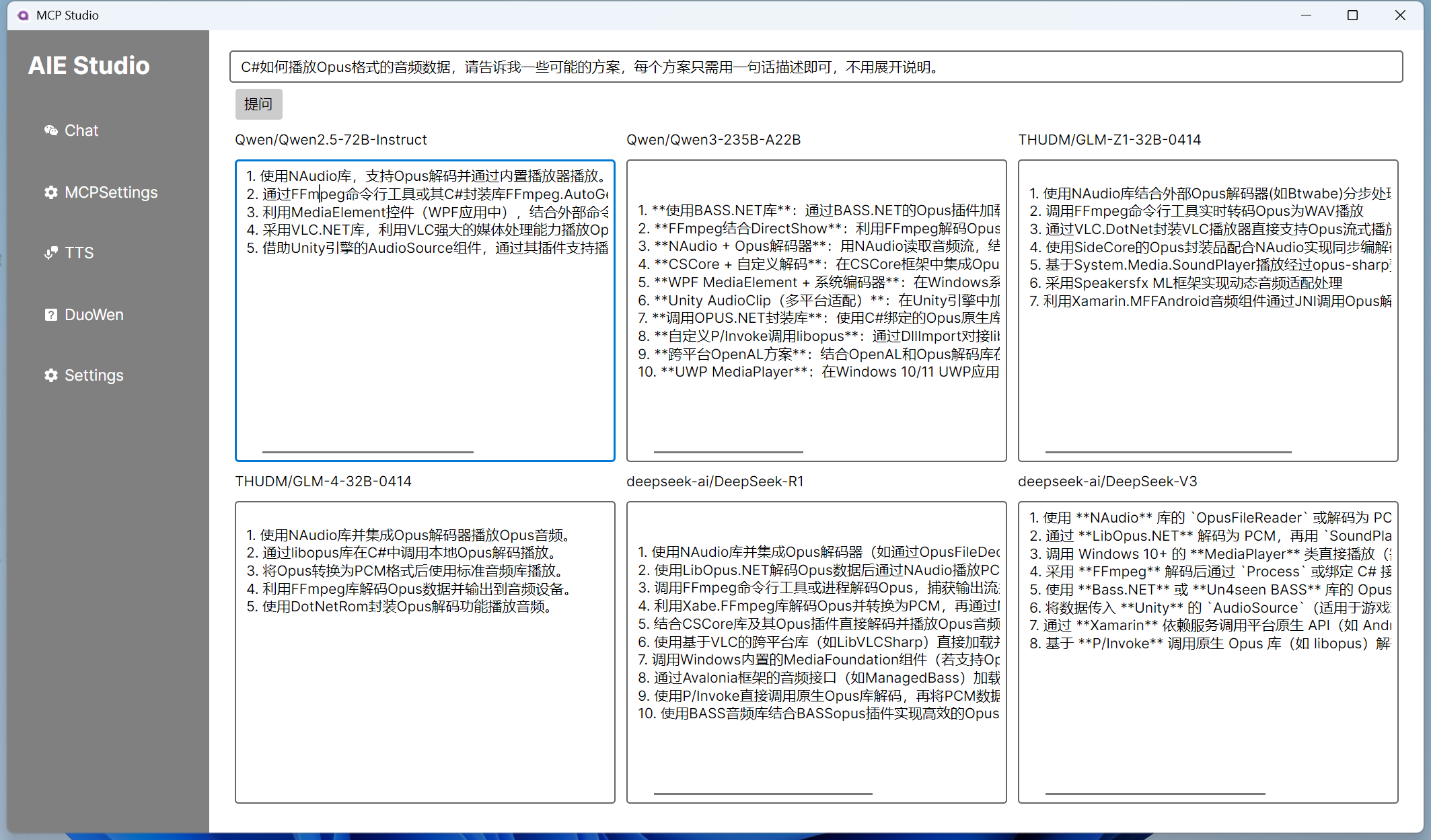
使用C#构建一个同时问多个LLM并总结的小工具
使用C#构建一个同时问多个LLM并总结的小工具
- 互联网
- 2026年06月19日
-
史上最霸气运动会口号
史上最霸气运动会口号
- 互联网
- 2026年06月19日
-
实战记录—PHP使用curl出错时输出错误信息
实战记录—PHP使用curl出错时输出错误信息
- 互联网
- 2026年06月19日
-
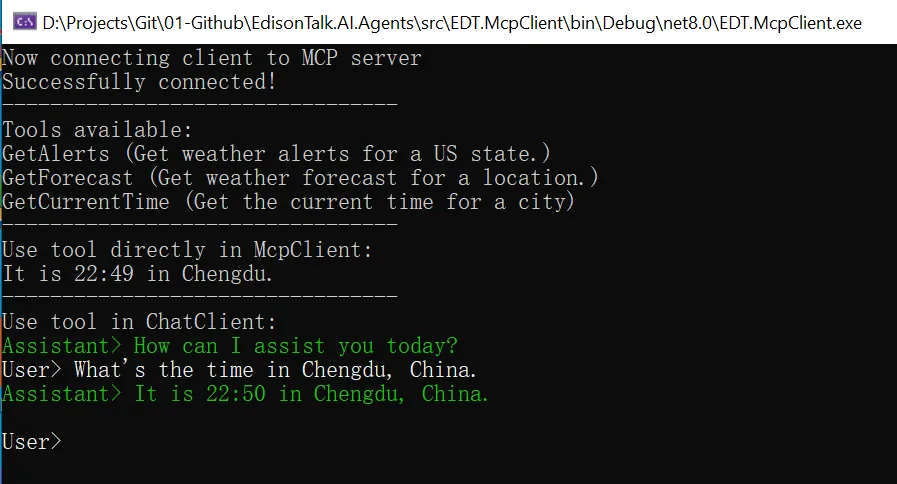
使用MCP C# SDK开发MCP Server + Client
使用MCP C# SDK开发MCP Server + Client
- 互联网
- 2026年06月19日
-
使用PHPStorm自带的Git版本控制,出现Git.exe占用内存过高
使用PHPStorm自带的Git版本控制,出现Git.exe占用内存过高
- 互联网
- 2026年06月19日
-
使用Vditor将Markdown文档渲染成网页(Vite+JS+Vditor)
使用Vditor将Markdown文档渲染成网页(Vite+JS+Vditor)
- 互联网
- 2026年06月19日