
1、mapreduce编程模型和mapreduce模型实现程序之间的关系
- 作者: 五速梦信息网
- 时间: 2026年05月04日 13:55
主要内容:
- mapreduce编程模型再解释;
- ob提交方式:
- windows->yarn
- windows->local ;
- linux->local
- linux->yarn;
- 本地运行debug调试观察
mapreduce体系很庞大,我们需要一条合适的线,来慢慢的去理解和学习。
1、mapreduce编程模型和mapreduce模型实现程序之间的关系1.1、mapreduce的编程模型
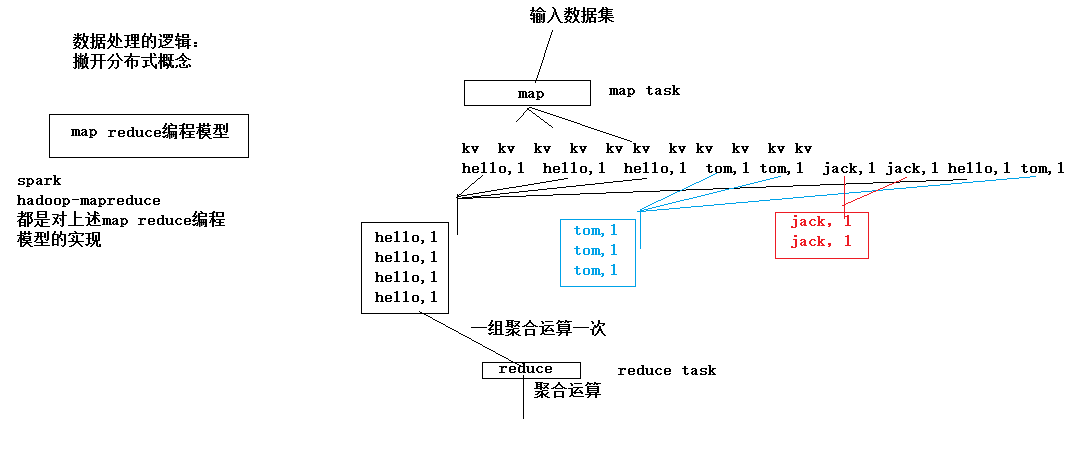
对mapreduce的总结:
如果只考虑数据处理的逻辑,撇开分布式的概念,其实mapreduce就只是一个编程模型了,而不是一个框架了。在这个编程模型里数据处理分为两个节点,一个map阶段一个reduce阶段。
map阶段要做的事情:就是吧原始的输入数据转换成大量的key-value数据,结合wordcont实例,key相同的数据会作为一组,形成若干组数据,接着就是这些组数据,一组一组的进行reduce阶段处理,每组reduce一次。
reduce阶段要做的事情:一组(key相同的数据)聚合运算一次。
一wordcount为例:数据被一行一行的读进来,按照空格进行拆分,将句子形成一个个(word,1)形式的键值对,map阶段就结束了;reduce阶段就是把单词相同的数据作为一组进行聚合,聚合逻辑就是把该组内的全部value累加在一起。
1.2、关系梳理
以上就是mapreduce的编程模型,编程模型并不能代表hadoop中的mapreduce框架,mapreduce编程模型其实就是一种典型的数据运算的逻辑模型,无论是hadoop-mapreduce运算框架也好,还是spark运算框架也好,都是具体的程序,都是对mapreduce编程模型的一种实现。而且hadoop中实现该模型时,在map阶段写了一个程序叫做map Task,在reduce 阶段写了一个程序叫做reduce Task;子spark里面,只不过时换了另外的名字,思想都一样。
以后在写mapreduce程序的时候,在写业务逻辑的时候只需要考虑编程模型就可以了,框架已经将实现上的一些东西都封装起来了,也就是说,要编写一个业务逻辑我们需要考虑的是,map将来产生什么样的key-vlue,将来相同的key就会作为一组没reduce聚合一次。
2、job提交方式2.1、windows-to-yarn / local
local:用于本地测试,无需打包成jar也无需提交。
若出现如下,错误,需要将hadoop配入window的环境变量中,同时将hadoop的bin目录配置到path中。

yarn:【比较繁琐】
目前为止我们需要写一个mapper实现类实现map阶段的逻辑,和写一个reduce实现类实现reduce阶段的 逻辑,和一个job提交器,提交job。
提交方式有多中,在上个笔记中,介绍了windows跨平台提交到yarn集群中,比较麻烦需要指定文件系统,需要知名job提交到哪里运行,还需要提供有权限的hdfs用户,还需要兼容跨平台。如下:
2.2、linux-to-yarn / local
若不配是上述参数直接将jar包上传到hadoop集群中的任何一台机器上,在linxu机器中运行jar包中的job提交器(自己写的jobsubmit),工具类会将jar包提交给local or(yarn,要看linux机器的配置参数是yarn还是local)无需在配置上述提到的参数,为什么呢?
使用hadoop jar命令而不是java -cp path1:path2... xxx.xx.xx.jobsubmiter
hadoop jar会把这台机器上的hadoop安装包中的所有jar包,以及所有配置文件都加载到本次运行java程序的classpath中。

这就是不用配置上述提到的参数,的原因,job提交工具程序中有一行代码如下,会将类路径下的配置信息全部加载进去,会将mapred-defalut.xml读入。
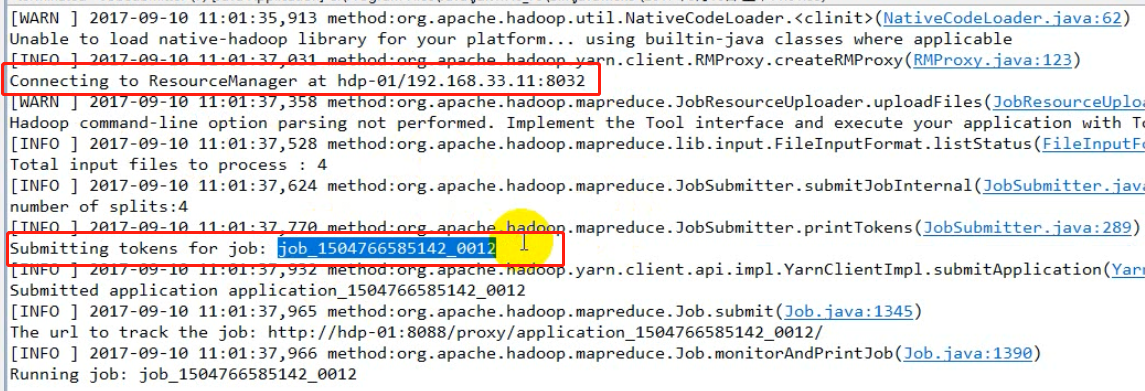
如下图,在window中提交job是,从日志信息可以看出,首先连接ResourceManager,连接成功之后ResourceManager为其指定本次的jobID。对比在linux中提交,发现linux中运行速度很快,而且没有日志显示连接ResourceManager,而且jobID也命名中有local字样,因为没有指定job提交到yarn集群,默认提交到了本地模拟器(LocalJobRunner)。因为参数mapreduce.framework.name默认locl。我们可以在代码中添加配置,无论提交到集群中的哪一台机子,都会去找yarn中的ResourceManager(配置文件中配置了地址),或者修改服务器的mapred-site.xml的参数值为yarn来覆盖jar包中mapred-default.xml中的local。
jar包中的mapred-defalut.xml中的默认值。



3.1、流量统计
现在有一批用户上网行为日志,需要统计日志记录中的用户上行流量和下行流量,以及流量总和;
需要统计多个value值时,可以考虑将多个value封装成一个valueBean对象,当然Bean对象需要实现hadoop的序列化接口(必须提供无参构造)
分析:Mapper<LongWritable, Text, Text, FlowBean>
Reducer<Text, FlowBean, Text, FlowBean>
3.1.1、自定义数据类型value
需要实现hadoop网络序列化接口,需要实现序列化和反序列化方法
本案例的功能:演示自定义数据类型如何实现hadoop的序列化接口
1、该类一定要保留空参构造函数
2、write方法中输出字段二进制数据的顺序 要与 readFields方法读取数据的顺序一致
3.1.2、自定义类型Key-Comparable
mapReduce的reduce在收集key-value的时候会按照key进行排序(内部排序机制),因此提供自定义得数据类型,作为key,必须实现比较接口和序列化接口,hadoop提供了一个合二为一的接口WritableComparable extend writable,Comparable
3.2、topK统计
现有一批url访问日志,统计出访问量最高的前5个网站。
分析:当存在不止1个reduceTask的时候,每个reduceTask拿到的数据都是局部信息,统计得到的结果也都是局部结果。
方案1:只提供一个reduce Task,使用数据量很小的时候
方案2:多阶段mapreduce当数据量很大的时候,上述方法就失去了分布式的优势,此时可以提供多阶段的mapReduce任务,下一次任务利用上一次产生的数据。
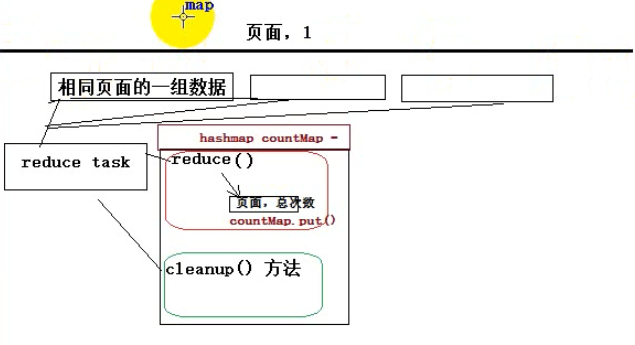
3.2.1、cleanup(Context context)
要点1:每一个reduce worker程序,会在处理完自己的所有数据后,调用一次cleanup方法
cleanup()函数的执行时机:假如该 reduceTask 接收到3组聚合数据,待3组数据的聚合工作都完成时候,会调用 一次cleanup()函数。
因此可以在cleanup()函数中进行结果排序,找出前几名。(TreeMap是有序的)
3.2.2、通过conf传参topK
要点2:如何向map和reduce传自定义参数
从JobSubmitter的main方法中,可以向map worker和reduce worker传递自定义参数(通过configuration对象来写入自定义参数);然后,我们的map方法和reduce方法中,可以通过context.getConfiguration()来取自定义参数
Configuration conf = new Configuration() //
这一句代码,会加载mr工程jar包中的hadoop依赖jar中的各默认配置文件*-default.xml
然后,会加载mr工程中自己的放置的*-site.xml
然后,还可以在代码中conf.set("参数名","参数值")
另外,mr工程打成jar包后,在hadoop集群的机器上,用hadoop jar mr.jar xx.yy.MainClass
运行时,hadoop jar命令会将这台机器上的hadoop安装目录中的所有jar包和配置文件通通加入运行时的classpath,
配置参数的优先级:
1、依赖jar中的默认配置
2、环境中的*-site.xml
3、工程中的*-site.xml
4、代码中set的参数
优先级一次增大,高优先级的参数值会覆盖低优先级的参数值
可以通过conf将参数传递到reducer中。
reducer方法有个参数Context context;context.getConfiguration()可以拿到job提交器中设置的参数。
传递方式有多多种
通过main函数传递参数
通过.xml配置文件传参
new Configration()默认加载core-default.xml core-site.xml 不会加载jar包里的hdfs-site.xml hdfs-default.xml,mapred-site.xml
可以加载自定义的xml文件
3.3、全局排序
方案1:一个reduceTask,添加一个缓存和:treeMap(内存:数据量不可太大),在cleanup(Context context)处理treeMap中的数据
方案2:多阶段mapreduce,上一个mapreduce产生的结果(eg:url 总次数)作为下一侧mapreduce的输入。同时利用mapreduce对key的排序机制。二阶段只是用一个reduceTask即可,当一阶段产生的数据也更十分巨大时候,二级同样可以设置多个reduceTask,但要对聚合数据的分发机制进行控制(控制数据分发:比如:大于1000w的都发给reduceTask A, 500w-1000w的发给 B)。
需求:统计request.dat中每个页面被访问的总次数,同时,要求输出结果文件中的数据按照次数大小倒序排序
关键技术点:
mapreduce程序内置了一个排序机制:
map worker 和reduce worker ,都会对数据按照key的大小来排序
所以最终的输出结果中,一定是按照key有顺序的结果
思路:
本案例中,就可以利用这个机制来实现需求:
1、先写一个mr程序,将每个页面的访问总次数统计出来
2、再写第二个mr程序:
map阶段: 读取第一个mr产生的结果文件,将每一条数据解析成一个java对象UrlCountBean(封装着一个url和它的总次数),然后将这个对象作为key,null作为value返回
要点:这个java对象要实现WritableComparable接口,以让worker可以调用对象的compareTo方法来进行排序
reduce阶段:由于worker已经对收到的数据按照UrlCountBean的compareTo方法排了序,所以,在reduce方法中,只要将数据输出即可,最后的结果自然是按总次数大小的有序结果
3.4、手机归属地分区
统计每一个用户的总流量信息,并且按照其归属地,将统计结果输出在不同的文件中
1、思路:
想办法让map端worker在将数据分区时,按照我们需要的按归属地划分
实现方式:自定义一个Partitioner
2、实现
先写一个自定义Paritioner
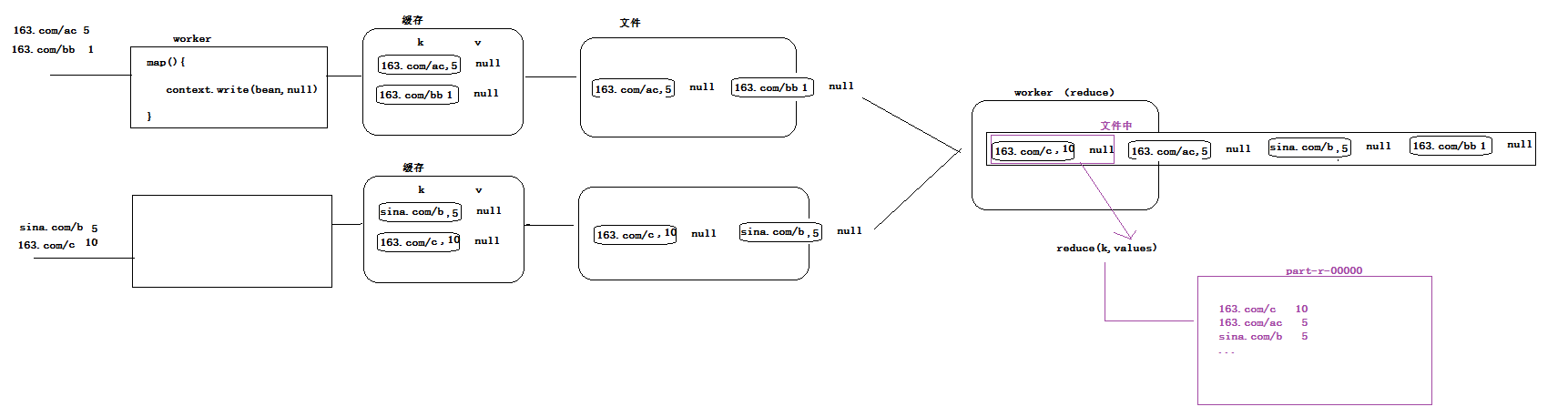
3.4.1、数据分发机制 Partitioner
决定mapTask产生的数据发给哪一个reduceTask,分发数据的动作有mapTask来完成,数据的分发逻辑有Partitioner指定。
分发数据的动作有mapTask来完成,数据的分发逻辑有Partitioner指定。
默认按照 key 的 hashcode % reduceTask个数

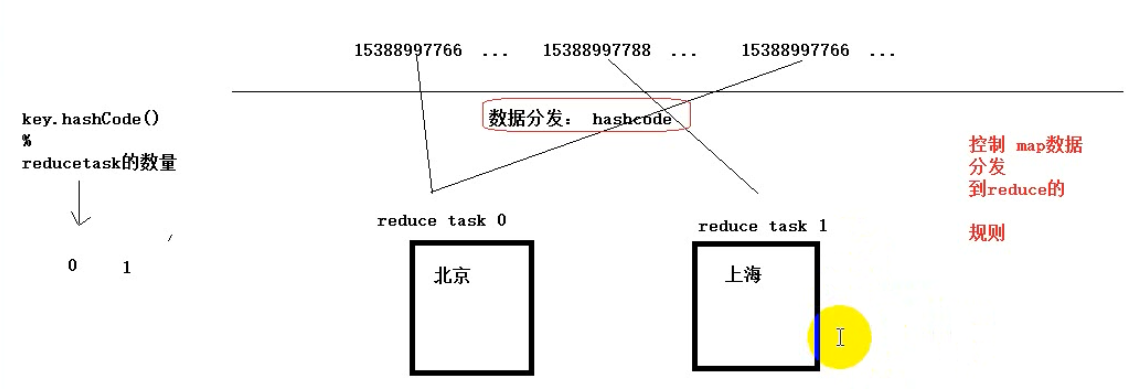
如果手机号作为key,但是要求同一个省的手机号要发给同一个reduceTask,这是就需要重新设计数据的分发机制。
一个规则在程序的世界里就是一个算法,一个算法在程序的世界里就是一段代码,一段代码在程序的世界里一定是封装在对象里的,一个对象在java的世界里一定是继承某个父类,或者是实现一个结构。
框架的灵活性就在于,我们一定可以自定义一个类来实现这个结构或者继承这个父类,提交给框架,改变原有的规则。
在job提交器中,指定数据分区逻辑
3.5、倒排索引
1、先写一个mr程序:统计出每个单词在每个文件中的总次数,
2、然后在写一个mr程序,读取上述结果数据:
map: 根据“-“”切,以单词做key,后面一段作为value
reduce: 拼接values里面的每一段,以单词做key,拼接结果做value,输出即可
| a.txt |
hello tom hello jim hello kitty hello rose |
hello-a.txt 4 hello-b.txt 4 hello-c.txt 4 java-c.txt 1 jerry-b.txt 1 jerry-c.txt 1 |
-> |
hello a.txt-->4 b.txt-->4 c.txt-->4 |
|
| b.txt |
hello jerry hello jim hello kitty hello jack |
-> |
java c.txt-->1 | ||
| c.txt |
hello jerry hello java hello c++ hello c++ |
jerry b.txt-->1 c.txt-->1 |
要点1:map方法中,如何获取所处理的这一行数据所在的文件名?
worker在调map方法时,会传入一个context,而context中包含了这个worker所读取的数据切片信息,而切片信息又包含这个切片所在的文件信息
那么,就可以在map中:
要点2:setup方法
worker在正式处理数据之前,会先调用一次setup方法,所以,常利用这个机制来做一些初始化操作;
3.5.1、数据切片
在mapTask创建之初就已经明确了要处理的切片,而且切片信息会被当作信息传递放在context(上下文,啥信息都有)中传递给map和reduce。
maptask和输入切片关系示意图:
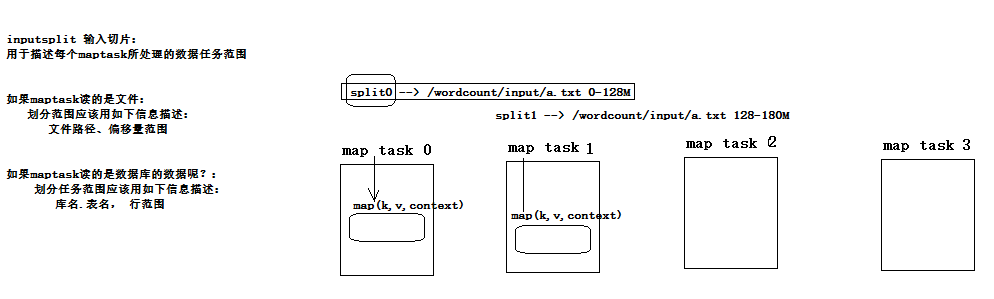
inputsplit是一个抽象类,mr框架在具体读数据的时候会调用不同的数据组件,比如文本组件,数据库组件,而不同的组件产生的数据切片split的描述信息是不同的。
3.6、分组topn
(排序控制,分区控制,分组控制)
|
order001,u001,小米6,1999.9,2 order001,u001,雀巢咖啡,99.0,2 order001,u001,安慕希,250.0,2 order001,u001,经典红双喜,200.0,4 order001,u001,防水电脑包,400.0,2 order002,u002,小米手环,199.0,3 order002,u002,榴莲,15.0,10 order002,u002,苹果,4.5,20 order002,u002,肥皂,10.0,40 |
需要求出每一个订单中成交金额最大的三笔
本质:求分组TOPN
思路1:
map阶段:order作为key,orderBean作为value
reduce阶段:
收集同一个key(orderID为key)的所有orderBean(实现接口WritableComparable<>),将其放入集合中,对集合进行排序,输出前n个。
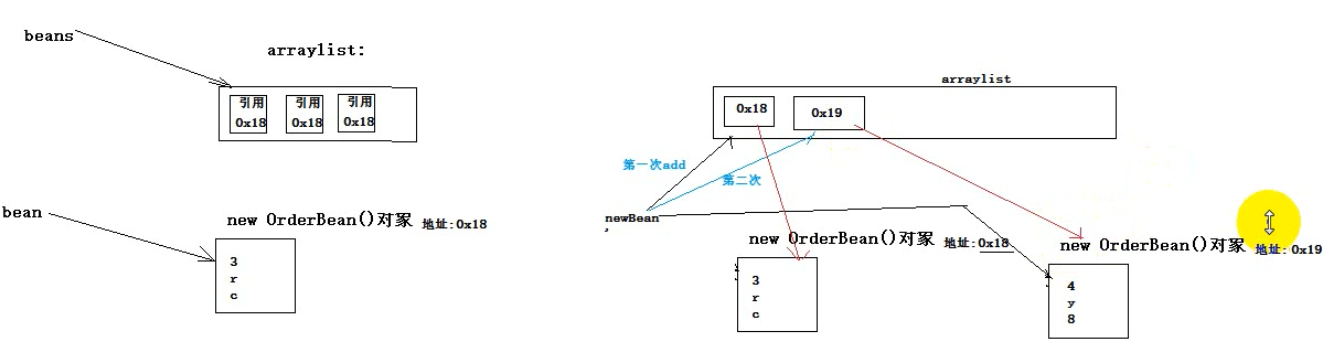
map中context.write(objectkey, objectvalue),,可以将objectkey提到成员变量的位置,每次在context.wirte之前,重新是指新的值,然后输出。context.wirte这里底层会将对象序列化并追加到临时的文件中去,而不会像在hashMap中反复add同一个不同修改值的对象。
mr框架是一定会执行,分区,排序,分组的,因此没有必要在思路1的reduce中排序,可以考虑利用框架的排序功能,如下
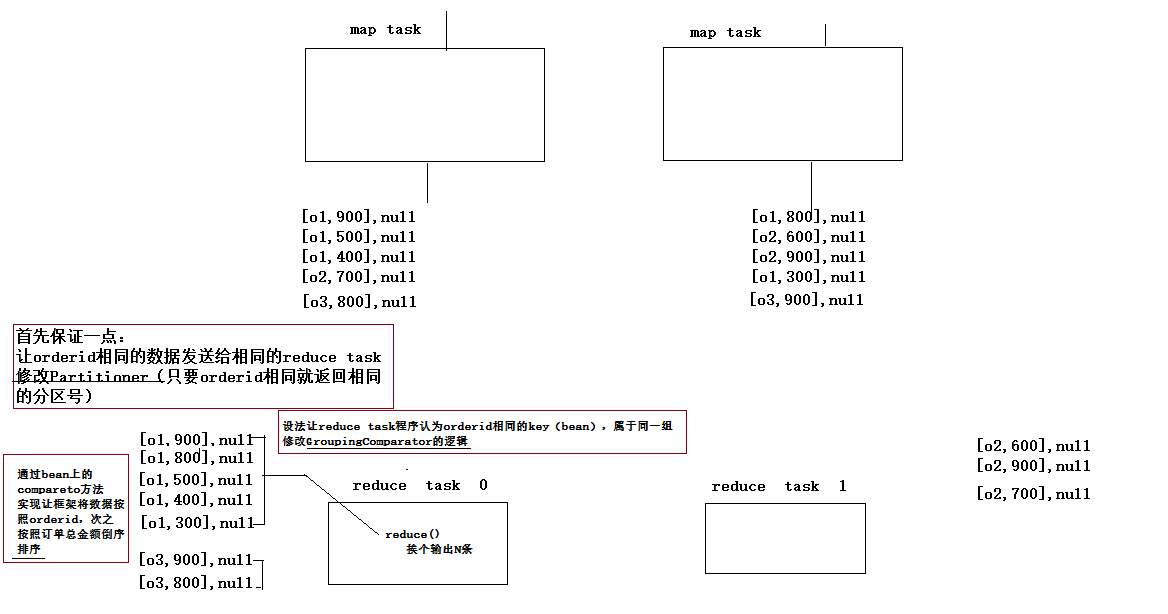
思路2:(见GroupingComparator)
实现思路:
map: 读取数据切分字段,封装数据到一个bean中作为key传输,key要按照成交金额比大小
reduce:利用自定义GroupingComparator将数据按订单id进行分组,然后在reduce方法中输出每组数据的前N条即可
3.6.1、序列化
如下:hashmap中会保留三个一样的引用
3.6.2、GroupingComparator-如何控制分组
在数据按照特定的分发规则发给reduceTask之前,数据会传递给mr框架,框架对收到的数据按照key自带的排序规则进行排序,接下来将数据发给对应的reduceTask,对数据统一组的数据进行一次聚合,这里就涉及一个分组机制GroupingComparator(内部有一个compare(obj1,obj2)方法),因为reduceTask需要知道哪些数据是同一组。
还以分组topn为例
mapreduce机制总结 数据分发Partitioner、key值排序Comparable、GroupingComparator
GroupingComparator应用示例--求分组topn
1、reduce中values迭代器,没迭代一次,key的值也会跟新一次
2、reduce会把mapTask传递过来的数据保存到硬盘文件中(数据量很大的时候内存中是放不下的),既然放在文件中,就会涉及序列化和反序列化。
3、GroupingComparator中必须要需要明确反序列化的类型
分组topn
orderBean
partitioner
groupcomparator
mr、job
3.7、共同好友
|
A:B,C,D,F,E,O |
-> |
one map: B是A的好友 B是E的好友 B是J的好友 reduce: (B:A E J) A-E:B A-J:B E-j:B |
-> |
two map: wirte(A-E,B) recude: A-E:B,?,? |
3.8、控制输入,输出
不仅仅局限于读取hdfs文件,可以替换数据输入组件和数据输出组件,对象可以是数据库等。
FileInputFormat
|--TextInputFormat
|--SequenceFileInputFormat
|--DBInputFormat
FileOutputFormat
|--TextOutputFormat
|--SequenceFileOutputFormat
SequenceFile文件是hadoop定义的一种文件,里面存放的是大量key-value的对象序列化字节(文件头部还存放了key和value所属的类型名);

3.9、 数据倾斜
将key特别多的那组数据分散个不同的reduce。这样一来recude聚合的数据就会是局部的,有可能需要在做一步mapreduce,得到全局的结果。
通用解决方案:将相同的key打散
具体做法:任何一个key都追加一个随机字符串/数字
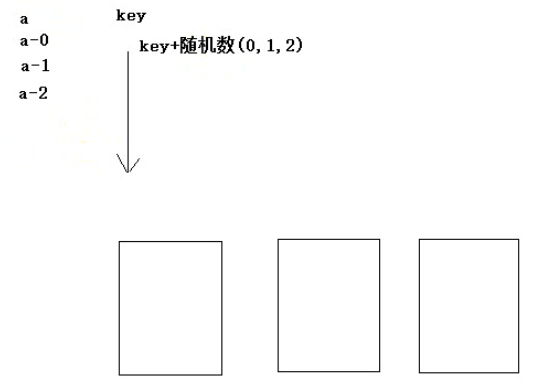
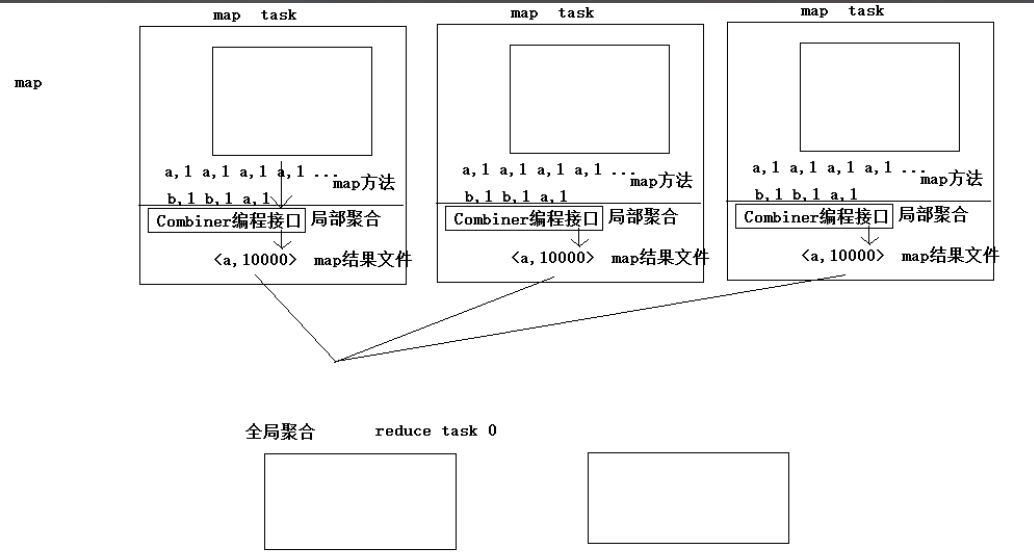
3.10、combiner
mapTask段可以利用combiner(直接使用reduce接口)进行局部聚合,reduceTask做的是全局聚合;
combiner主要用来避免mapTask产生大量数据,占用网络带宽,形成性能瓶颈;
当然也可以用来解决数据倾斜
3.11、join场景
订单信息在一张表,用户信息在一张表;现要将用户信息追加到点单表中。
4、mapreduce内部核心机制原理mr框架如何控制分区
mr框架如何控制排序
mr框架如何扣控制分组
mr框架如何输入输出组件
map逻辑
reduce逻辑
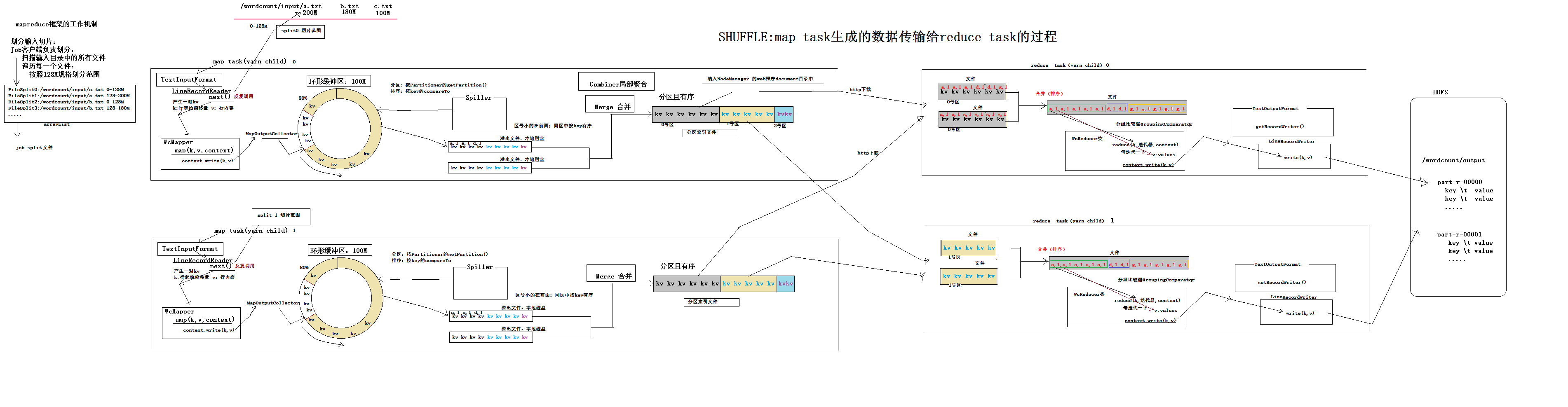
4.1、mapreduce框架内部核心工作机制详解
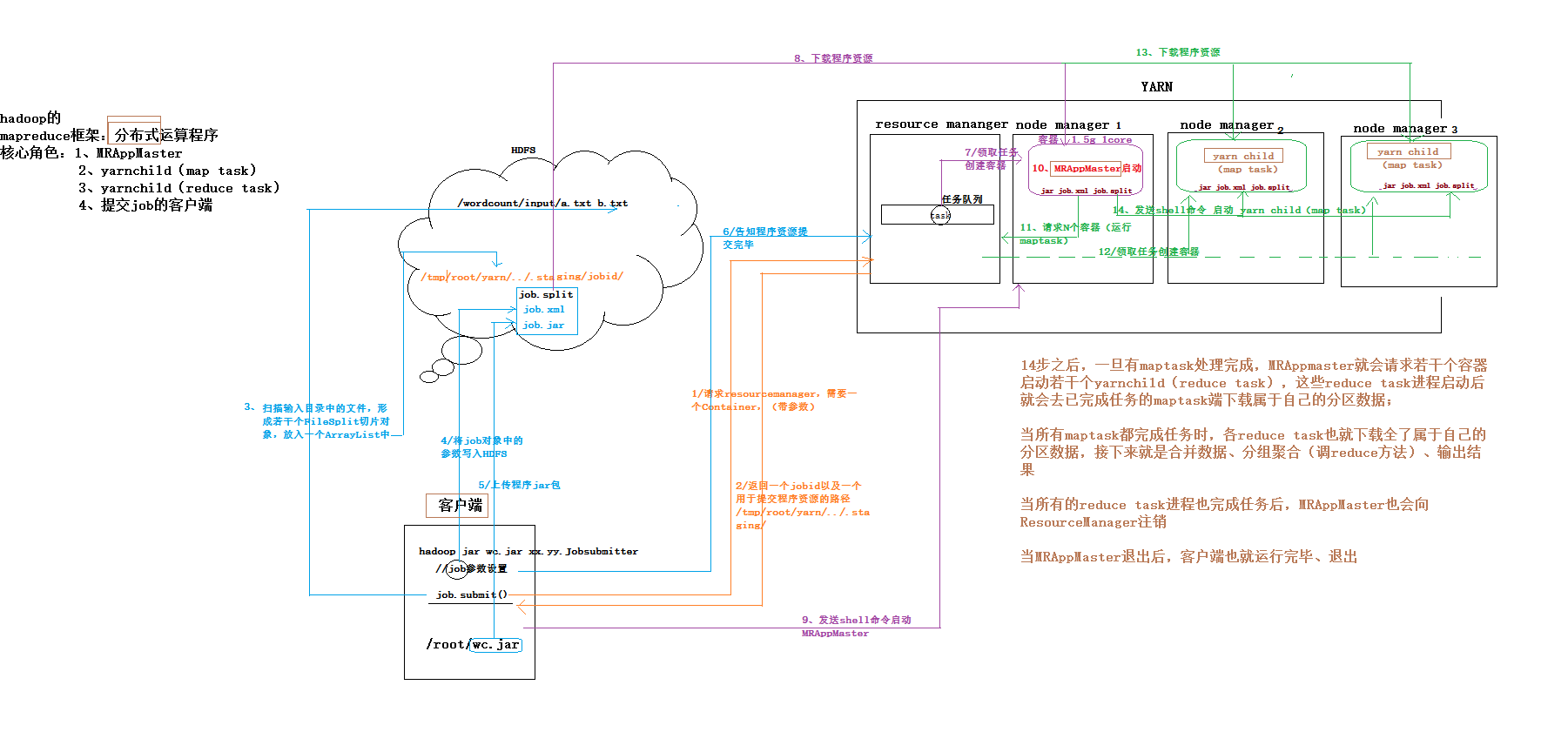
4.2、mapreduce程序在YARN上启动-运行-注销的全流程
mrappmaster
4.2.1、yarn的资源参数配置
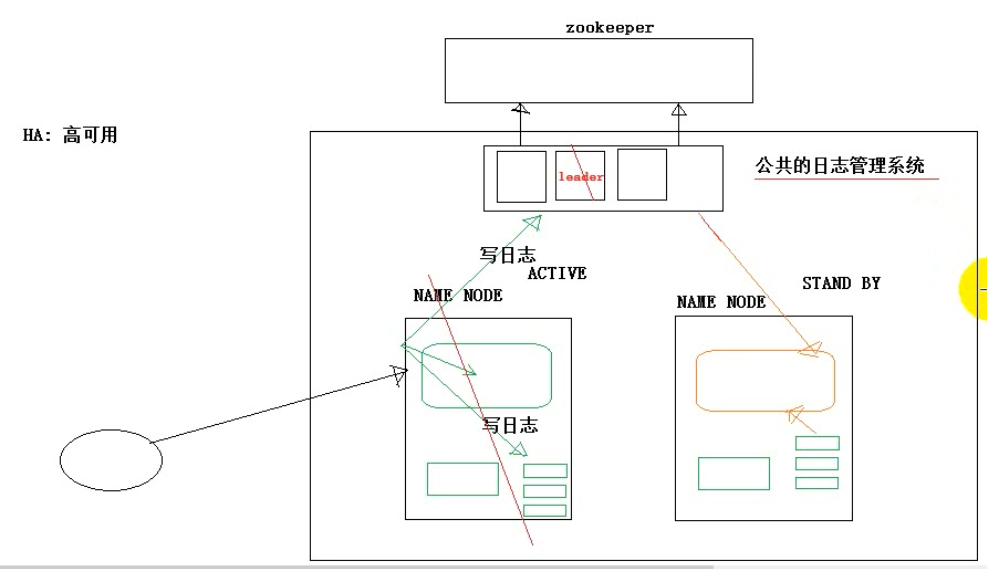
4.3、Hadoop-HA机制整体解析

相关文章
-
1、线性DP 213. 打家劫舍 II
1、线性DP 213. 打家劫舍 II
- 互联网
- 2026年05月04日
-

1. 《progress》 进度条
1. 《progress》 进度条
- 互联网
- 2026年05月04日
-
1. Redis分布式锁原理
1. Redis分布式锁原理
- 互联网
- 2026年05月04日
-
1 时间戳 2 C# 如何生成一个时间戳 3 js 时间加一分钟... 4 js string
1 时间戳 2 C# 如何生成一个时间戳 3 js 时间加一分钟... 4 js string
- 互联网
- 2026年05月04日
-

1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
- 互联网
- 2026年05月04日
-
01.使用File类读写文件
01.使用File类读写文件
- 互联网
- 2026年05月04日







