
es hash路由算法
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:46
es hash路由算法
- 2024-08-18
主要知识点 1.document路由到shard的理解及原理 2.路由算法:shard = hash(routing) % number_of_primary_shards 3.routing值(_id or custom routing value) 4.primary shard创建之后不可变的原因 一.document路由到shard理解及原理 在es中,一个index会被分片,一个index中存在很多document,这个document存放在不同的shardK ,而一个docu
1. 什么是Memcached 要了解Memcached首先要到官网上去看官方对它的描述.Memcached的官网网站是:http://memcached.org/,官方对Memcached的描述如下图: 从官方的描述中可以总结出,Memcached是一个高性能分布式的内存对象缓存系统.它将数据以key-value形式存储的存储在内存中,极大的提高了效率.但是Memcached的缺点在于不支持持久化(不支持写入磁盘),所以一旦断电,内存中的全部数据都会丢失.而Redis弥补了这个缺点,既在内存中
无刷新页面,切换视图,用hash 实现路由切换,本身附带history记录,简单舒服. 最近用vue,看到vue-route的路由,做单页应用切换视图真心易如反掌,分分钟爽到不行.为了加深理解其内涵原理,遂决意写一个最简单的hash 路由. 思路很简单,自己维护一个 hash route 的哈希表,通过注册路由及其处理事件,通过hashchange来触发对应事件处理,有点像观察者模式的思想,先注册,再派发. 实现方法 maps 批量注册 add 单条注册 remove 单条删除 clear 全部
出处:http://blog.csdn.net/v_JULY_v 第一部分:Top K 算法详解问题描述百度面试题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节. 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个.一个查询串的重复度越高,说明查询它的用户越多,也就是越热门.),请你统计最热门的10个查询串,要求使用的内存不能超过1G. 必备知识: 什么是哈希表? 哈希
哈希连接(HASH JOIN) 前文提到,嵌套循环只适合输出少量结果集.如果要返回大量结果集(比如返回100W数据),根据嵌套循环算法,被驱动表会扫描100W次,显然这是不对的.看到这里你应该明白为 什么有些SQL优化了跑几秒,没优化跑几个小时甚至跑1天都不出结果.返回大量结果集适合走HASH JOIN.HASH JOIN算法非常复杂,这里就不讨论了 下面看一个HASH JOIN的例子(基于SCOTT,Oracle11gR2) SQL> select * from table(dbms_xpla
博客地址:https://ainyi.com/69 三月来了,春天还会远吗.. 在这里,隆重宣布本博客告别 Vue 传统的 hash 路由,迎接好看而优雅的 history 路由~~ 映照官方说法 vue-router 默认 hash 模式 -- 使用 URL 的 hash 来模拟一个完整的 URL,于是当 URL 改变时,页面不会重新加载 如果不想要很丑的 hash,我们可以用路由的 history 模式,这种模式充分利用 history.pushState API 来完成 URL 跳转而无须
路由就是指随着浏览器地址栏的变化,展示给用户的页面也不相同. 早期的路由都是后端实现的,直接根据 url 来 reload 页面,页面变得越来越复杂服务器端压力变大,随着 ajax 的出现,页面实现非 reload 就能刷新数据,也给前端路由的出现奠定了基础.我们可以通过记录 url 来记录 ajax 的变化,从而实现前端路由.(可以根据不同的url来展示不同的页面,很好的优化了页面的交互体验.)目前有两种方式: 1:H5的history的新API(pushstate.replacestate.
域名查询顺序: a. 浏览器缓存(本机hosts文件),浏览器会缓存DNS记录一段时间. b. 系统缓存 c. 路由器缓存 d. 检查ISP e. 递归搜索域名服务器 路由算法: 一.静态路由算法 a.泛射路由算法(扩散法) b.固定路由算法 c.随机走动法(Random Walk) d.最短路径法(Shortest Path,SP) 二.动态路由算法(自适应路由算法) a.分布式路由选择 b.集中式路由选择 c.混合式动态路由选择 d.链路状态路由算法
Hash表算法处理海量数据处理面试题 主要针对遇到的海量数据处理问题进行分析,参考互联网上的面试题及相关处理方法,归纳为三种问题 (1)数据量大,内存小情况处理方式(分而治之+Hash映射) (2)判断元素是否在集合中(布隆过滤器+BitMap) (3)各种TOPN(存储和各种排序) 经典问题分析 上千万or亿数据(有重复),统计其中出现次数最多的前N个数据,分两种情况:可一次读入内存,不可一次读入. 可用思路:trie树+堆,数据库索引,划分子集分别统计,hash,分布式计算,近似统计,外排序
Hash表定义 散列表(Hash table,也叫哈希表),是根据关键字值(Key value)直接进行访问的数据结构.也就是说,它通过把关键字(关键字通过Hash算法生成)映射到表中一个位置来访问记录,以加快查找的速度.这个映射函数叫做散列函数,存放记录的数组叫做散列表. 给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数. Hash算法定义 哈希算法将任意长度的二
开篇吹牛..... 不吹了,因为我不擅长算法,就不胡说八道了. 现在一般的实现负载均衡,主要采用2种方法: 1.轮训 2.负载均衡算法 轮训就不说了,负载均衡现在一般采用HASH一致算法 不多说了,这个算法方面我真不擅长,不给大家胡说.介绍2片博文 https://www.cnblogs.com/daizhj/archive/2010/08/24/1807324.html https://www.cnblogs.com/mushroom/p/4472369.html 由于我是往负载均衡方面
我们由一个简单的问题逐步入手:有一个庞大的字符串数组,然后给你一个单独的字符串,让你从这个数组中查找是否有这个字符串并找到它,你会怎么做?有一个方法最简单,老老实实从头查到尾,一个一个比较,直到找到为止,我想只要学过程序设计的人都能把这样一个程序作出来,但要是有程序员把这样的程序交给用户,我只能用无语来评价,或许它真的能工作,但...也只能如此了. 最合适的算法自然是使用HashTable(哈希表),先介绍介绍其中的基本知识,所谓Hash,一般是一个整数,通过某种算法,可以把一个字符串"压缩&q
链接地址:https://blog.csdn.net/ma1kong/article/details/2662997 1.查看MessageDigest源码的注释说明 2.和hash一致性算法 什么关系 3.使用场景
什么是hash,什么是哈希,什么是hash散列,什么是hash一致性算法
出处:http://blog.csdn.net/v_JULY_v. 说明:本文分为三部分内容, 第一部分为一道百度面试题Top K算法的详解:第二部分为关于Hash表算法的详细阐述:第三部分为打造一个最快的Hash表算法. ------------------------------------ 第一部分:Top K 算法详解 问题描述 百度面试题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节. 假设目前有一千万个
当我们在做 SPA 应用的时候,为了兼容老的浏览器(如IE9)我们不得不放弃 HTML5 browser history api 而只能采用 hash 路由的这种形式来实现前端路由,但是因为 hash 被路由占据了,导致本来不是问题的锚点功能却成了一个不大不小的问题. 经过我自己的搜索目前有两种方式能够解决这个问题,为了能在 react 生态下面简单优雅的使用,我专门封装了一个锚点组件 react-anchor-without-hash,它使用了类似原生 a 标签的写法,并且可以支持滚动的距离和
热门专题
相关文章
-
es,创建schedule
es,创建schedule
- 互联网
- 2026年06月03日
-
ES5对Array增强的9个API
ES5对Array增强的9个API
- 互联网
- 2026年06月03日
-
ES6+ 现在就用系列(二):let 命令
ES6+ 现在就用系列(二):let 命令
- 互联网
- 2026年06月03日
-
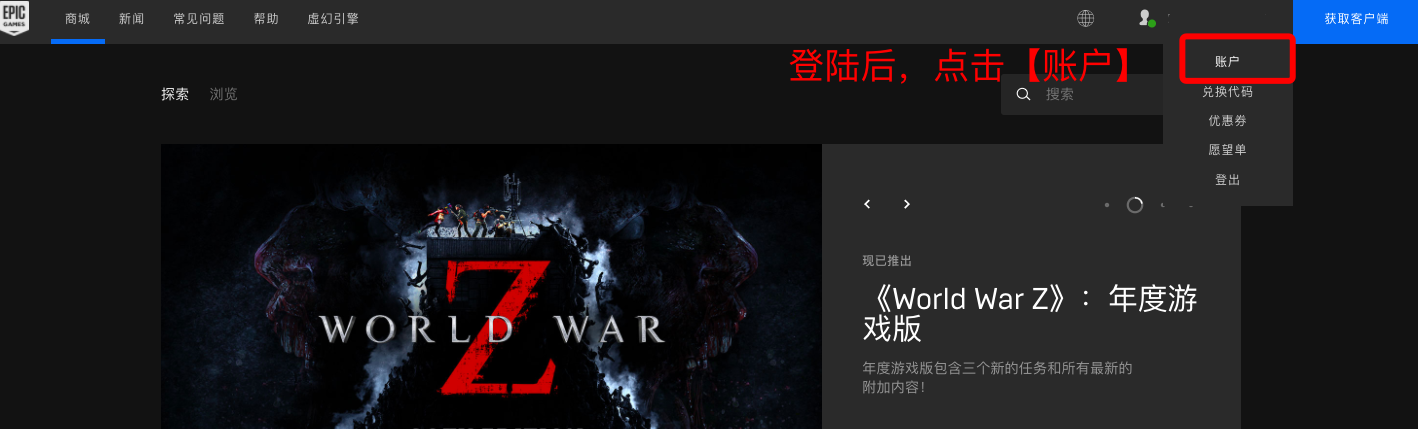
epic游戏平台如何启用认证器应用程序二次验证码谷歌身份验证器?
epic游戏平台如何启用认证器应用程序二次验证码谷歌身份验证器?
- 互联网
- 2026年06月03日
-
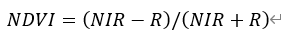
ENVI大气校正方法反演Landsat 7地表温度
ENVI大气校正方法反演Landsat 7地表温度
- 互联网
- 2026年06月03日
-
Enum 枚举值 (一) 获取描述信息
Enum 枚举值 (一) 获取描述信息
- 互联网
- 2026年06月03日



