
hive 计算去年同期
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:44
hive 计算去年同期
- 2024-08-28
1.to_date:日期时间转日期函数 select to_date('2015-04-02 13:34:12');输出:2015-04-02122.from_unixtime:转化unix时间戳到当前时区的时间格式 select from_unixtime(1323308943,’yyyyMMdd’);输出:20111208123.unix_timestamp:获取当前unix时间戳 select unix_timestamp();输出:1430816254select unix_timest
一.前言 Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎.至于为什么提高了计算速度,可以参考下图: 用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS. Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能. 二.安装包准备 1)下载tez的依赖包:http://tez.apache.org 2)拷贝apache-tez-
hive表结构例如以下: create table pv_user_info( session_id string, user_id string, url string, starttime bigint ); 主要就是这几个字段实用.省略其它. 实现方式:userid和sessionid分组后并按时间降序排序,降序排序后.第一行就是该用户最后一次浏览的网页.最后一行是第一次浏览的网页,第一行的starttime和第二行的starttime相减就是第二行停留时间. 这里会有几个误差 用户最后一
首先,hive本身有一个UDF,名字是datediff.我们来看一下这个日期差计算的官方描述,(下面这个是怎么出来的): hive> desc function extended datediff; OK datediff(date1, date2) - Returns the number of days between date1 and date2 date1 and date2 are strings in the format 'yyyy-MM-dd HH:mm:ss' or 'yyy
目录 一.背景 二.算法 1. 第一步:排序 2. 第二步:第二列与第三列做日期差值 3. 第三步:按第二列分组求和 4. 第四步:求最大次数 三.扩展(股票最大涨停天数) 强哥说他发现了财富密码,最近搞了一套股票算法,其中有一点涉及到股票连续涨停天数的计算方法,我们都知道股票周末是不开市的,这里有个断层,需要一点技巧.我问是不是时间序列,他说我瞎扯,我也知道自己是瞎扯.问他方法,他竟然不告诉我,这么多年的兄弟情谊算个屁.真当我没他聪明吗,哼! 靠人不如靠自己,我决定连夜研究一下在Hive里面计
hive 的存储路径的 .hive-staging_hive_yyyy-MM-dd_HH-mm-ss_SSS_xxxx-x 文件可以清理掉吗 https://blog.csdn.net/sparkexpert/article/details/51918999 https://www.v2ex.com/t/317114 http://www.aboutyun.com/thread-20657-1-1.html
-- 计算指定日期本周的第一天和最后一天 select day ,dayofweek(day) as dw1 ,date_add( - dayofweek(day)) as Su_s -- 周日_start ,date_add( - dayofweek(day)) as Sa_e -- 周六_end , end as dw2 ,date_add( end) as Mo_s -- 周一_start ,date_add( end) as Su_e -- 周日_end from ( select '2
package com.grady import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, Row, SparkSession} object HiveTableToTable { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("StuToStu2") val sp
) FreeMarker --',-7)?date('yyyy-MM-dd'),'week')?string('yyyy-MM-dd')}'
关注公众号:大数据技术派,回复: 资料,领取1024G资料. 目录 时间滑动计算 外部调用实现时间循环 自关联实现滑动时间窗口 扩展基于自然周的的滚动时间窗口计算 总结 时间滑动计算 今天遇到一个需求大致是这样的,我们有一个业务涉及到用户打卡,用户可以一天多次打卡,我们希望计算出7天内打卡8次以上,且打卡时间分布在4天以上的时间,当然这只是个例子,我们具体解释一下这个需求 用户一天可以打卡多次,所以要求打卡必须分布在4天以上: 7天不是一个自然周,而是某一天和接下来的6天,也就是说时间是是滑动的
转自http://www.alidata.org/archives/622 使用Hive可以高效而又快速地编写复杂的MapReduce查询逻辑.但是某些情况下,因为不熟悉数据特性,或没有遵循Hive的优化约定,Hive计算任务会变得非常低效,甚至无法得到结果.一个”好”的Hive程序仍然需要对Hive运行机制有深入的了解. 有一些大家比较熟悉的优化约定包括:Join中需要将大表写在靠右的位置:尽量使用UDF而不是transfrom……诸如此类.下面讨论5个性能和逻辑相关的问题,帮助你写出更好的H
遇到个情况,跑hive级联insert数据报错,可以尝试换个hive计算引擎 hive遇到FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask错误 .配置mapreduce计算引擎 set hive.execution.engine=mr; .配置spark计算引擎 set hive.execution.engine=spark; .配置tez 计算引擎 set hive.
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hive分析数据底层的实现是MapReduce 3)执行程序运行在Yarn上 1. Hive架构原理 hive的组成: 可以配置Hive运行引擎Tez: https://www.cnblogs.com/shengyang17/p/10527700.html 2. Hive安装及配置 ()把apache-
(1)Hive 数仓中一些常用的dt与日期的转换操作 下面总结了自己工作中经常用到的一些日期转换,这类日期转换经常用于报表的时间粒度和统计周期的控制中 日期变换: (1)dt转日期 to_date(from_unixtime(unix_timestamp('${dt}','yyyyMMdd'))) (2)日期转dt regexp_replace('${date}','-','') (3)dt转当月1号日期 to_date(from_unixtime(unix_timestamp(concat(s
补充说明 left outer join where is not null与left semi join的联系与区别:两者均可实现exists in操作,不同的是,前者允许右表的字段在select或where子句中引用,而后者不允许. 除了left outer join,Hive QL中还有right outer join,其功能与前者相当,只不过左表和右表的角色刚好相反. 另外,Hive QL中没有left join.right join.full join以及right semi join
分别安装hive 和 hbase 1.在hive中创建与hbase关联的表 create table ganji_ranks (row string,num string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:num") TBLPROPERTIES ("h
随着移动互联网.云计算.物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代.数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产.如何处理大数据,挖掘大数据的价值,让大数据为企业的发展保驾护航,将是未来信息技术发展道路上关注的重点. 传统的数据处理方式通常是将数据导入至专门的数据分析工具中,这样会面临两个问题:1.如果源数据非常大时,往往数据的移动就要花费较长时间.2.传统的数据处理工具往往是单机模型,面对海量数据时,数据处理的时间也是一个很大
一.安装及配置 官方文档: https://cwiki.apache.org/confluence/display/Hive/GettingStarted 安装Hive2.3 1)上传apache-hive-2.3.0-bin.tar.gz 到/opt/software目录下,并解压到/opt/module [test@hadoop102 software]$ tar -zxvf apache-hive-2.3.6-bin.tar.gz -C /opt/module/ 2)修改apache-hi
目录 关于外部依赖文件找不到的问题 为什么要使用外部依赖 为什么idea 里面可以运行上线之后不行 依赖文件直接打包在jar 包里面不香吗 学会独立思考并且解决问题 继承DbSearcher 读取文件传入字节数组 总结 关注公众号:大数据技术派,回复"资料",领取1000G资料. 其实这篇文章的起源是,我司有数据清洗时将ip转化为类似中国-湖北-武汉地区这种需求.由于ip服务商提供的Demo,只能在本地读取,我需要将ip库上传到HDFS分布式存储,每个计算节点再从HDFS下载到本地.
Hadoop版本演进 当前Hadoop有两大版本:Hadoop 1.0和Hadoop 2.0. Hadoop1.0被称为第一代Hadoop,由分布式文件系统HDFS和分布式计算框架MapReduce组成,其中,HDFS由一个NameNode和多个DataNode组成,MapReduce由一个JobTracker和多个TaskTracker组成,对应Hadoop版本为0..x..x.其中0..x是比较稳定的版本,最后演化为1. x,变成稳定版本..x则增加了NameNode HA等新特性. 第二代
热门专题
- 上一篇: Hive分区和分桶的区别
- 下一篇: Hive 导出数据到 MySQL
相关文章
-
Hive分区和分桶的区别
Hive分区和分桶的区别
- 互联网
- 2026年06月03日
-
hive用RTRIM
hive用RTRIM
- 互联网
- 2026年06月03日
-
home assitant和微信小程序的对接教程
home assitant和微信小程序的对接教程
- 互联网
- 2026年06月03日
-
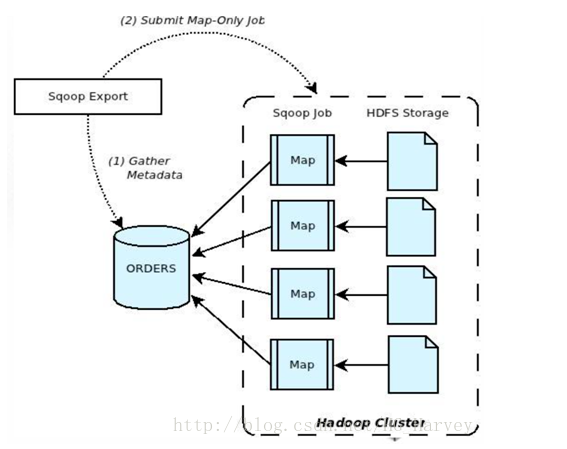
Hive 导出数据到 MySQL
Hive 导出数据到 MySQL
- 互联网
- 2026年06月03日
-
hiho #1288 微软2016.4校招笔试题 Font Size
hiho #1288 微软2016.4校招笔试题 Font Size
- 互联网
- 2026年06月03日
-
Hibernate之一级缓存和二级缓存
Hibernate之一级缓存和二级缓存
- 互联网
- 2026年06月03日



