
java提取文字训练字库
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:38
java提取文字训练字库
- 2024-10-31
网上很多教程没有介绍清楚tessdata的位置,以及怎么配置,并且对中文库的描述也存在问题,这里介绍一个最简单的样例. 1.使用maven,直接引入依赖,确保你的工程JDK是1.8以上 <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.3.1</version> </dep
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇文章继续深入学习tesseract-ocr识别图片中的中文. 一,准备中文字库 下载chi_sim.traindata字库.要有这个才能识别中文.下好后,放到Tesseract-OCR项目的tessdata文件夹里面.(注意下载字库,一定要看库对应的tesseract版本下载) 为什么强调版本呢 ,
软件下载:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/ 官方字库下载:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#format-of-traineddata-files 建议:普通版本和FX版本都下载,用普通版本调整坐标,用FX版本调整汉字识别.FX版本的坐标调整不能输入数字,一旦坐标偏移太大,简直就是反人类设计. 另外,也可以直接使用普通版本
0.目标 很多特殊场景,原生的字库识别率不高,这时候就需要根据需求自己训练字库生成traineddata文件. 一.前期准备工作 1.安装jdk 用于运行jTessBoxEditor 2.安装jTessBoxEditor 用于调整图片上文字的内容和位置 3. 安装tesseract5.0 jdk下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html jTessBox
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一.准备工作 1.下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行. 2.下载chi_sim.traindata字库.要有这个才能识别中文.下好后,放到Tesseract-OCR项目的tessdata文件夹里面. 3.下载jTessBoxEditor,这个是用来训练字库
关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一.准备工作 1.下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行. 最后下载4.0版本 2.下载chi_sim.traindata字库.要有这个才能识别中文.下好后,放到Tesseract-OCR项目的tessdata文件夹里面. https://github.com
转自:https://www.cnblogs.com/lcawen/articles/7040005.html 关于中文的识别,效果比较好而且开源的应该就是Tesseract-OCR了,所以自己亲身试用一下,分享到博客让有同样兴趣的人少走弯路. 文中所用到的身份证图片资源是百度找的,如有侵权可联系我删除. 一.准备工作 1.下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行,Windows下:https://github.com/UB-Mannheim/tesse
package folder; import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.HashMap;import java.util.Iterator;import java.util.Map; public class f
Java提取Url中某个参数的值. public static String getParam(String url, String name) { String params = url.substring(url.indexOf("?") + 1, url.length()); Map<String, String> split = Splitter.on("&").withKeyValueSeparator("=").s
现在图片文字识别已经很成熟了,比如qq长按图片,点击图片识别就可以识别图片的文字,将不认识的.文字数量大的.或者不能赋值的值进行二次可复制功能. 我们现在就基于百度Ai开放平台进行个人文字识别,demo使用的是C#控制台应用程序,后续有需要的可以嫁接到指定项目中使用,比如提供选择图片,点击识别, 获取返回的值.废话不多说,上干货: 总体为: 注册百度账号api,创建自己的应用: 创建vs控制台应用程序,引入动态链接库: 编写代码调试,效果图查看: 总结. 1.创建百度AI文字识别应用 在百度
文中测试了3.0和4.0两个版本.发现3.0识别效率不准确,需要训练词库.4.0识别效率就比较高了,而且支持结果生成pdf.txt等格式.所以推荐使用4.0版本. 这个工具可以用在爬虫的时候获取验证码进行识别且自动输入验证码的功能. git地址:https://github.com/tesseract-ocr/tesseract 下载地址:https://digi.bib.uni-mannheim.de/tesseract/ 1.下载安装 我下载的是 3.05.01,自带了中文词库. 下载完成后
字符训练网上一搜一大堆,但作为一个初学者而言,字符合并网上却写的很笼统 首先,需要 生成的字符集.tif文件,位置文件 .box ,只要有这两个文件在,就可以合并字典(这个说的很有道理的样子) 好了,我现在有三个需要合并的字典 (1).(why3.楷体.exp0.tif,why3.楷体.exp0.box) (2).(why4.microsoftyaheiuilight.exp0.tif,why4.microsoftyaheiuilight.exp0.box) (3). (why5.隶书b.ex
一.准备工作 需要的文件 tif文件和box文件. 如果你打标打好了,但是是分批次打标的,那么可以合并字库,我们最初只需要 tif 和 box 文件,如下: 二.生成对应的 .tr 训练文件 根据不同的tif文件依次使用下面这个命令 tesseract qyc.word.exp4.tif qyc.word.exp4 nobatch box.train 完成后效果是这样的,每个组合都会有一个对应的 .tr 文件 三.从所有文件中提取字符 unicharset_extractor fst.word.
工具类 Patterns.java 1 package com.util; 2 3 import java.util.regex.Matcher; 4 import java.util.regex.Pattern; 5 6 /** 7 * Commonly used regular expression patterns. 8 */ 9 public class Patterns { 10 /** 11 * Regular expression to match all IANA top-lev
放假了,终于可以继续可以静下心写一写OCR方面的东西.上次谈到文字的切割,今天打算总结一下我们怎么得到用于训练的文字数据集.如果是想训练一个手写体识别的模型,用一些前人收集好的手写文字集就好了,比如中科院的这些数据集.但是如果我们只是想要训练一个专门用于识别印刷汉字的模型,那么我们就需要各种印刷字体的训练集,那怎么获取呢?借助强大的图像库,自己生成就行了! 先捋一捋思路,生成文字集需要什么步骤: 确定你要生成多少字体,生成一个记录着汉字与label的对应表. 确定和收集需要用到的字体文件. 生成
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的离线包,建议默认安装 上面一个是中文的语言包,如果网络可以FQ的童鞋可以在安装的时候就选择语言包在线安装,有多种语言可供选择,默认只有英文的 exe安装好之后,把上面一个文件拷到安装目录下tessdata
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的离线包,建议默认安装 上面一个是中文的语言包,如果网络可以FQ的童鞋可以在安装的时候就选择语言包在线安装,有多种语言可供选择,默认只有英文的 exe安装好之后,把上面一个文件拷到安装目录下tessdata文件夹下 如C:\Program Files (x86)\Tesseract-OCR\tessd
今天意外的看到一个可以提取图片中文字的网站,自己试了下,提取效果还不错 网址为: https://zhcn.109876543210.com/ 现在有图片如下 我想从中提取的文字 1.打开网址,上传图片 2.选择语言与输出格式 3.开始转换 4.转换结果 5.下载结果 转换出来后差异是有一点,但是不太大
内容简介 本文主要介绍使用ZipFile来提取zip压缩文件中特定后缀(如:png,jpg)的文件并保存到指定目录下. 导入包:import java.util.zip.ZipFile; 如需添加对rar压缩格式的支持,请参考我的另一篇文章:https://www.cnblogs.com/codecat/p/11078485.html 实现代码(仅供参考,请根据实现情况来修改) /** * 将压缩文件中指定后缀名称的文件解压到指定目录 * @param compressFile 压缩文件 * @
本文将介绍通过Java来提取或读取Word文档中文本和图片的方法.这里提取文本和图片包括同时提取文档正文当中以及页眉.页脚中的的文本和图片. 使用工具:Free Spire.Doc for Java (免费版) Jar文件导入方法(参考): 方法1:下载jar文件包.下载后解压文件,并将lib文件夹下的Spire.Doc.jar文件导入到java程序.导入效果参考如下: 方法2:可通过maven导入.参考导入方法. 测试文档如下: Java代码示例(供参考) [示例1]提取Word中的文本 im
今天主要学了一些类似c中的一些语句,java也是一样类似的,只有一些点需要稍微注意一下,一些语句是新增的需要知道. 完完全全新学的知识就是class和instance的区别.如何创建实例.数据的封装.定义方法.调用方法.private方法.构造方法和方法重载. 关于雅思做了CEPT测试,也只有A2的成绩,之前测E9的时候也是只有4-4.5的成绩,加油呀,目标7呢. 训练题:今天复习了一下bfs+prim+递归,每天复习一点点,总能赶超的.只是需要改的就是做题速度,实在是太慢了,提高专注度. 感觉
热门专题
相关文章
-
JAVA通过JDBC连接Oracle数据库详解【转载】
JAVA通过JDBC连接Oracle数据库详解【转载】
- 互联网
- 2026年06月03日
-
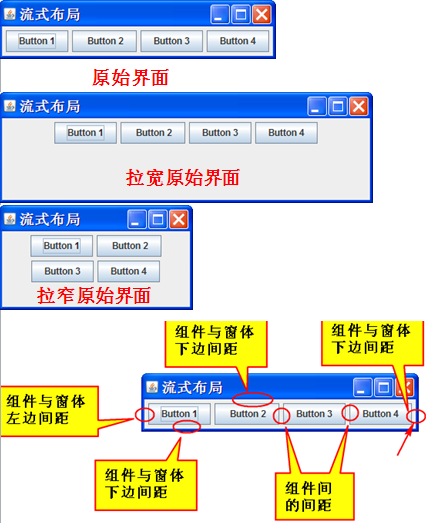
Java图形化界面设计——布局管理器之FlowLayout(流式布局)
Java图形化界面设计——布局管理器之FlowLayout(流式布局)
- 互联网
- 2026年06月03日
-
java五子棋设计流程图
java五子棋设计流程图
- 互联网
- 2026年06月03日
-
java输入输出流与文件操作实验小结
java输入输出流与文件操作实验小结
- 互联网
- 2026年06月03日
-
Java使用velocity导出word
Java使用velocity导出word
- 互联网
- 2026年06月03日
-
java实现sftp客户端上传文件夹的功能
java实现sftp客户端上传文件夹的功能
- 互联网
- 2026年06月03日



