
python webdrive浏览器
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:35
python webdrive浏览器
- 2024-08-28
Python+selenium打开或关闭浏览器 一.打开或关闭火狐浏览器 1. 初始化一个webdriver实例对象driver,然后打开和关闭firefox浏览器.要用selenium打开fiefox浏览器,首先下载一个driver插件geckodriver.exe 2. 获取路径:https://github.com/mozilla/geckodriver/releases,根据自己的电脑进行选择 3. 下载完成后并解压,解压之后将geckodriver.
selenium + python 多浏览器测试 支持库包 在学习 Python + Selenium 正篇之前,先来看下对多浏览器模拟的支持.目前selenium包中已包含webdriver,help(webdriver) 查看其下package:也可以查看源文件
想用python模拟浏览器访问web的方法测试些东西,有哪几种方法呢? 一类:单纯的访问web,不解析其js,css等. 1. urllib2 #-*- coding:utf-8 -* import urllib2 def Furllib2(ip,port,url,timeout): proxydict = {} proxydict['http'] = "http://%s:%s"%(ip,port) print proxydict proxy_handler = urllib2.Pr
Python实现浏览器自动化操作 (2012-08-02 17:35:43) 转载▼ 最近在研究网站自动登录的问题,涉及到需要实现浏览器自动化操作,网上有不少介绍,例如使用pamie,但是只是支持IE,而且项目也较久没有更新了.还有就是利用selenium,可支持多种浏览器.网上资料比较多.经过比较,我选择了Splinter模块,因为利用Splinter开发浏览器自动化操作,编写代码比较简单.一.Splinter的安装Splinter的使用必修依靠Cython.lxml.selenium
一.python 打开浏览器的方法: . startfile方法(打开指定浏览器) import os os.startfile("C:\Program Files\internet explorer\iexplore.exe") . system方法 打开指定浏览器: import os os.system('"C:\Program Files\internet explorer\iexplore.exe"') 通过指定浏览器打开指定的网址: import os
第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求 selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以还得需要下载对应浏览器的操作软件 操作原理是:selenium模块操作浏览器操作软件,浏览器操作软件操作浏览器 Selenium 2.0适用于以
一.python 打开浏览器的方法: 1. startfile方法(打开指定浏览器) import os os.startfile("C:\Program Files\internet explorer\iexplore.exe") 2. system方法 打开指定浏览器: import os os.system('"C:\Program Files\internet explorer\iexplore.exe"') 通过指定浏览器打开指定的网址: import o
在用浏览器进行网页访问时,会向网页所在的服务器发送http协议的GET或者POST等请求,在请求中除了指定所请求的方法以及URI之外,后面还跟随着一段Request Header.Request Header的内容主要用于描述本地信息,如所用的浏览器.所用的系统.语言.所能接受的返回数据的编码格式等,其中有一个非常重要的Header项就是Cookie,Cookie可以说是网站的自定义数据集.由于服务器端无法无法控制本地(浏览器)的内存数据,但服务器又有必要搜集与自己所提供的服务相关的本地状态信息
一. 引言 在<第14.6节 Python模拟浏览器访问网页的实现代码>介绍了使用urllib包的request模块访问网页的方法.但上节特别说明http报文头Accept-Encoding最好不设置,否则服务端会根据该字段及服务端的情况采用对应方式压缩http报文体,如果爬虫应用没有解压支持会导致应用无法识别收到的响应报文体.本节简单介绍一下怎么处理响应报文体的压缩. 在爬虫爬取网页时,如果在请求头中传递了"'Accept-Encoding':'gzip'"信息则服务器会
每天都要登陆某网站,刷积分.为了节省时间,用了下python中的webbrowser模块.新建.py 文件 #!/usr/bin/python import webbrowser webbrowser.open_new_tab('url') 然后执行chmod 修改文件属性. 接着运行.感觉省了好几步操作啊:) note: webbrowser.open_new('url') 是新建默认浏览器的窗口,而上面的是新建一个已打开浏览器的tab.
#! /usr/bin/env python # -*-coding:utf- -*- import urllib import urllib2 import cookielib class NetRobot: def __init__(self, baseurl): self.cj = cookielib.CookieJar() self.baseurl = baseurl self.opener = urllib2.build_opener(urllib2.HTTPCookieProcess
在用浏览器进行网页访问时,会向网页所在的服务器发送http协议的GET或者POST等请求,在请求中除了指定所请求的方法以及URI之外,后面还跟随着一段Request Header.Request Header的内容主要用于描述本地信息,如所用的浏览器.所用的系统.语言.所能接受的返回数据的编码格式等,其中有一个非常重要的Header项就是Cookie,Cookie可以说是网站的自定义数据集.由于服务器端无法无法控制本地(浏览器)的内存数据,但服务器又有必要搜集与自己所提供的服务相关的本地状态信息
1.启用浏览器 browser = webdriver.Chrome() 谷歌浏览器 browser = webdriver.Firefox() 火狐浏览器 browser = webdriver.IE() IE浏览器 2.浏览器操作 browser.refresh() 刷新浏览器 browser.back()
#! /usr/bin/env python # encoding=utf8 import webbrowser import time webbrowser.open("http://www.baidu.com") # wait a while, and then go to another page time.sleep(5) webbrowser.open("http://www.taobao.com") webbrowser 模块提供了一个到系统标准 web
最近需要使用浏览器模拟访问页面,同时需要使用不同的ip访问,这个时候就考虑到在使用浏览器的同时加上ip代理. 本篇工作环境为win10,python3.6. Chorme 使用Chrome浏览器模拟访问,代码如下 import time from selenium import webdriver url = "https://www.cnblogs.com/" driver = webdriver.Chrome("D:/tools/wedriver/chromedriver
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以还得需要下载对应浏览器的操作软件 操作原理是:selenium模块操作浏览器操作软件,浏览器操作软件操作浏览器 Selenium 2.0适用于以下浏览器 Google Chrome Internet Explorer 7, 8, 9, 10, 11 Firefox Safari Opera Html
1 .浏览器最大化我们知道调用启动的浏览器不是全屏的,这样不会影响脚本的执行,但是有时候会影响我们“观看”脚本的执行. #coding=utf-8 from selenium import webdriver import time browser = webdriver.Firefox() browser.get("http://www.baidu.com") print "浏览器最大化" browser.maximize_window() #将浏览器最大化显示
# -*- coding:utf-8 -*- import os import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys """ 练习启动各种浏览器:Firefox, Chrome, IE 练习启动各种浏览器的同时加载插件:Firefox, Chrome, IE """ def startFirefox(): &q
两种思绪三种要领: 用pamie.建议不要使用,因为pamie为小我私人开发,里面的bug比力多,并且是直接使用win32com体式格局的,如果ie不警惕修改了,后果很严重.另外,pamie3使用的是python3,这个在python世界中撑持的不太好. 用selenium rc.这个东东大好,如果用这个东东完成网页自动实验正确,撑持多种浏览器,并且是公司开发的,上手难易程度类似pamie.只不过需要打开浏览器,这个就看大家的需要了. 用mechanize和beautiful soup.这个东东
此处以chromdriver为例,放置driver路径问题参看上一篇问题.和java处理差不多,python实现静默运行方式如下 首先解答为什么进行静默运行? 我们在本地一般便于调试可以用GUI界面运行浏览器,但是在服务器上我们就只能用非GUI模式运行,因为服务器一般是linux环境没有可视化界面的浏览器 代码如图: 源码: from selenium import webdriver option=webdriver.ChromeOptions()option.add_argument("he
热门专题
相关文章
-
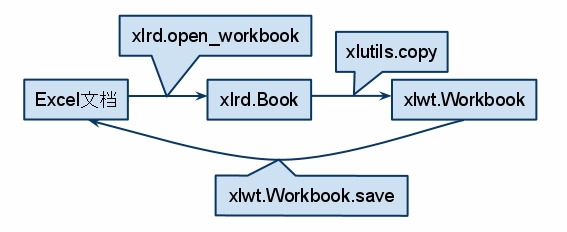
Python xlrd、xlwt、xlutils修改Excel文件
Python xlrd、xlwt、xlutils修改Excel文件
- 互联网
- 2026年06月03日
-
python xlwt 怎么删除工作表
python xlwt 怎么删除工作表
- 互联网
- 2026年06月03日
-
python 按照模板输出
python 按照模板输出
- 互联网
- 2026年06月03日
-
python unicode转义
python unicode转义
- 互联网
- 2026年06月03日
-
python treeview 设置单元格的值
python treeview 设置单元格的值
- 互联网
- 2026年06月03日
-
python tick
python tick
- 互联网
- 2026年06月03日



