
python 词频统计自定义词库
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:36
python 词频统计自定义词库
- 2024-09-04
首先在网上下载一个汉语词典的txt文件, 汉语词典 1.用正则去掉词语的解释,即提取出所有汉语词语: import re def getHanYuCi(st): p = re.compile(r'[.*?]') # 挑选出: [汉字] rt = p.findall(st) p = re.compile(r'[\u4E00-\u9FA5]+') # 去掉[]:只保留汉字; *:前一个字符0次或无限次; +:表示1次或无限制 rt = p.findall(str(rt)) #print(str[0:
word: https://github.com/ysc/word word-1.3.1.jar 需要JDK8word-1.2.jar c语言给解析成了“语言”,自定义词库必须为UTF-8 程序一旦运行,停不下来!百度上百的主要是这个word分词,除了作者的微示例,没有别的例子,感觉全是作者自吹自擂出来的,不好用. import java.util.List; import org.apdplat.word.WordSegmenter; import org.apdplat.word.dicti
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如果我想根据自己的公司名称来查询,如“好记性不如烂笔头感叹号博客园” 如果我想根据自己公司里的产品名称来查询,如“” 如果我想根据某个网络上流行的词名称来查询,如“扫福” 那么,若直接使用es-ik则分不出来的,所以,这就是为什么需要es-ik的自定义词库的缘由啦! [hadoop@HadoopMas
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用来配置自定义词库 main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起 quantifier.dic:放了一些单位相关的词 suffix.dic:放了一些后缀 surname.dic:中国的姓氏 stopword.dic:英文停用词 ik原生最重要的两个
主要知识点: 知道IK默认的配置文件信息 自定义词库 一.ik配置文件 ik配置文件地址:es/plugins/ik/config目录 IKAnalyzer.cfg.xml:用来配置自定义词库 main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起 quantifier.dic:放了一些单位相关的词 suffix.dic:放了一些后缀 surname.dic:中国的姓氏 stopword.dic:英文停用词 ik原生最重要的两个
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze { "analyzer": "standard", "text": "中华人民共和国" } 我们想要的效果是什么:"中华人民共和国"作为一整个词语. 得到的结果是: { "tokens" :
一,分词系统地址:https://github.com/NLPchina/ansj_seg 二,为什么选择ansj? 1.项目需求: 我们平台要做手机售后的舆情分析,即对购买手机的用户的评论进行分析.分析出手机每个模块(比如:相机,充电等.这些大模块还需要细分,比如充电又可以分:充电慢,没有快充等)的好差评,并且计算差评率,供开发后续改进.之前一直是人工分析,随着评论的增加,这一块也是一个很大的工作量.因此我们想到了做评论的自动分析.这就要用到自然语言处理的技术了. 2.ansj的优点 分词效率
1) 博客开头给出自己的基本信息,格式建议如下: 学号2017****7128 姓名:肖文秀 词频统计及其效能分析仓库:https://gitee.com/aichenxi/word_frequency1 2) 程序分析,对程序中的四个函数做简要说明.要求附上每一段代码及对应的说明. process_file作用:打开文件,读取文件到缓冲区,关闭文件 # 读文件到缓冲区 def process_file(file_name): try: # 打开文件 file_read=open(file_na
需要包:IKAnalyzer2012_FF_hf1.jarlucene-core-5.5.4.jar需要文件: IKAnalyzer.cfg.xmlext.dicstopword.dic 整理好的下载地址:http://download.csdn.net/detail/talkwah/9770635 import java.io.IOException; import java.io.StringReader; import org.wltea.analyzer.cfg.Configuratio
利用Python做一个词频统计 GitHub地址:FightingBob [Give me a star , thanks.] 词频统计 对纯英语的文本文件[Eg: 瓦尔登湖(英文版).txt]的英文单词出现的次数进行统计,并记录起来 代码实现 import string from os import path with open('瓦尔登湖(英文版).txt','rb') as text1: words = [word.strip(string.punctuation).lower() for
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于HTTP 的管理界面.Solr已经在众多大型的网站中使用,较为成熟和稳定.Solr 包装并扩展了Lucene,所以Solr的基本上沿用了Lucene的相关术语.更重要的是,Solr 创建的索引与 Lucene搜索引擎库完全兼容.通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以
统计某几个词在文章出现的次数 -file参数分发,是从客户端分发到各个执行mapreduce端的机器上 1.找一篇文章The_Man_of_Property.txt如下: He was proud of him! He could not but feel that in similar circumstances he himself would have been tempted to enlarge his replies, but his instinct told him that t
1.jieba 库 -中文分词库 words = jieba.lcut(str) --->列表,词语 count = {} for word in words: if len(word)==1: continue else: count[word] = count.get(word,0)+1 函数 jieba.lcut() 分词,中文 2. 英文分词库 str = "ab sld dd" str.split() 3.词云统计 import wordcloud c = wor
-cacheArchive也是从hdfs上进分发,但是分发文件是一个压缩包,压缩包内可能会包含多层目录多个文件 1.The_Man_of_Property.txt文件如下(将其上传至hdfs上) hadoop fs -put The_Man_of_Property.txt /mapreduce Preface “The Forsyte Saga” was the title originally destined for that part of it which is called “The
-cacheFile 分发,文件事先上传至Hdfs上,分发的是一个文件 1.找一篇文章The_Man_of_Property.txt: He was proud of him! He could not but feel that in similar circumstances he himself would have been tempted to enlarge his replies, but his instinct told him that this taciturnity wa
它在哪里呢? 非常重要! [hadoop@HadoopMaster custom]$ pwd/home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/custom[hadoop@HadoopMaster custom]$ lltotal 5252-rw-r--r--. 1 hadoop hadoop 156 Dec 14 10:34 ext_stopword.dic-rw-r--r--. 1 hadoop hadoop 130 Dec 14 1
Python词频分析 一.前言 在日常工作或者生活中,有时候会遇到词频分析的场景.如果是要进行词频分析,那么首先需要对句子进行分词,将句子中的单词进行切割并按照词性进行归类. 在Python中有个第三方库叫jieba(结巴),可以对文章或者语句进行分词.不得不佩服这个库的作者,真是个取名鬼才:) 二.分词 2.1 安装库 jieba库github地址 jieba库官方给出了3中安装库的方式,分别如下: 全自动安装: easy_install jieba 或者 pip install jieba
由于项目中要用到词库,而下载的搜狗词库是.scel格式,所以就用python脚本将搜狗词库.scel格式文件转化为.txt格式文件. #!/bin/python # -*- coding: utf-8 -*- import struct import sys import binascii import pdb try: reload(sys) sys.setdefaultencoding('utf-8') except: pass # 搜狗的scel词库就是保存的文本的unicode编码,每两
热门专题
- 上一篇: python 存数据 txt
- 下一篇: python 查找当前目录下文件后缀
相关文章
-
python 存数据 txt
python 存数据 txt
- 互联网
- 2026年06月03日
-
python 带参数 请求
python 带参数 请求
- 互联网
- 2026年06月03日
-
python 发送 get、post 、webscoket
python 发送 get、post 、webscoket
- 互联网
- 2026年06月03日
-
python 查找当前目录下文件后缀
python 查找当前目录下文件后缀
- 互联网
- 2026年06月03日
-
python 变量类型
python 变量类型
- 互联网
- 2026年06月03日
-
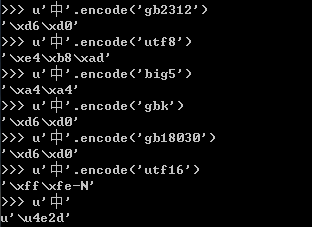
Python 编码简单说
Python 编码简单说
- 互联网
- 2026年06月03日



