
Redis基础用法、高级特性与性能调优以及缓存穿透等分析
- 作者: 五速梦信息网
- 时间: 2026年06月03日 13:32
一、Redis介绍
Redis是一个开源的,基于内存的结构化数据存储媒介,可以作为数据库、缓存服务或消息服务使用。Redis支持多种数据结构,包括字符串、哈希表、链表、集合、有序集合、位图、Hyperloglogs等。Redis具备LRU淘汰、事务实现、以及不同级别的硬盘持久化等能力,并且支持副本集和通过Redis Sentinel(哨兵)实现的高可用方案,同时还支持通过Redis Cluster(集群)实现的数据自动分片能力。
Redis的主要功能都基于单线程模型实现,也就是说Redis使用一个线程来服务所有的客户端请求,同时Redis采用了非阻塞式IO,并精细地优化各种命令的算法时间复杂度,这些信息意味着:
Redis是线程安全的(因为只有一个线程),其所有操作都是原子的,不会因并发产生数据异常
Redis的速度非常快(因为使用非阻塞式IO,且大部分命令的算法时间复杂度都是O(1))
使用高耗时的Redis命令是很危险的,会占用唯一的一个线程的大量处理时间,导致所有的请求都被拖慢。(例如时间复杂度为O(N)的KEYS命令,严格禁止在生产环境中使用)
二、Redis数据结构及常用的命令
3、List
jedis.del()jedis.del()八 缓存穿透、缓存击穿、缓存雪崩、热点数据失效
在我们的平常的项目中多多少少都会使用到缓存,因为一些数据我们没有必要每次查询的时候都去查询到数据库。特别是高 QPS 的系统,每次都去查询数据库,对于你的数据库来说将是灾难。我们使用缓存时,我们的业务系统大概的调用流程如下图:
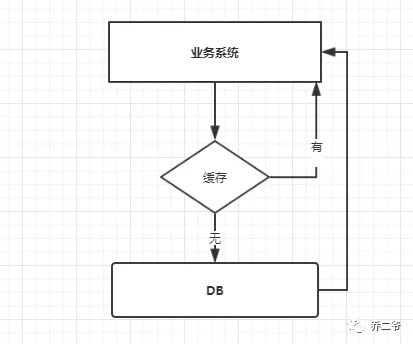
当我们查询一条数据时,先去查询缓存,如果缓存有就直接返回,如果没有就去查询数据库,然后返回。这种情况下就可能会出现一些现象。
1、缓存穿透
(1)什么是缓存穿透
正常情况下,我们去查询数据都是存在。那么如果去查询一条数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,那么请求每次都会打到数据库上面去。这种查询不存在数据的现象我们称为缓存穿透。这时如果有黑客会对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉。
(2)解决方案
1、缓存空值
之所以会发生穿透,就是因为缓存中没有存储这些空数据的key,从而导致每次查询都到数据库去了。那么我们就可以为这些key对应的值设置为null 丢到缓存里面去。后面再出现查询这个key 的请求的时候,直接返回null 。这样,就不用在到数据库中去走一圈了,这种解决方案需要给每一个不存在的key设置一个相对较短的过期时间。
2、布隆过滤器
将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回,存在再走查缓存 -> 查 DB。流程如下:
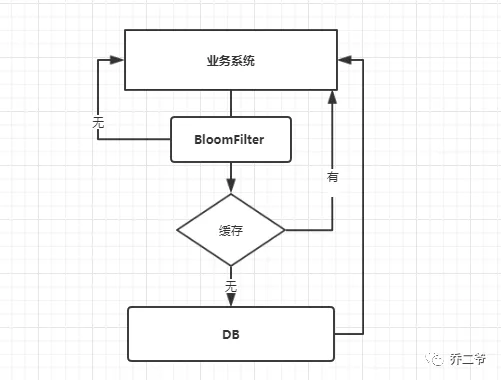
3、如何选择
针对于一些恶意攻击,攻击带过来的大量key 是不存在的,那么我们采用第一种方案就会缓存大量不存在key的数据。此时我们采用第一种方案就不合适了,我们完全可以先对使用第二种方案进行过滤掉这些key。针对这种key异常多、请求重复率比较低的数据,我们就没有必要进行缓存,使用布隆过滤器直接过滤掉。
而对于空数据的key有限的,重复率比较高的,我们则可以采用缓存空值方式进行缓存。
2、缓存击穿
(1)什么是缓存击穿
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。这种现象我们称为缓存击穿。会造成某一时刻数据库请求量过大,压力剧增。
与缓存穿透的区别是:
缓存穿透是数据在缓存和数据库中都不存在。
缓存击穿是数据存在,只是刚好数据在缓存中超时失效。
(2)解决方案
上面的现象是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁 来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
3、缓存雪崩
(1)什么是缓存雪崩
缓存雪崩的情况是说,当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了或者有多个key同时过期,会有大量的请求进来直接打到DB上面。结果就是DB 撑不住,挂掉。
(2)解决办法
1、事前:
1)使用集群缓存,保证缓存服务的高可用
这种方案就是在发生雪崩前对缓存集群实现高可用,如果是使用 Redis,可以使用 主从+哨兵或者Redis Cluster 来避免 Redis 全盘崩溃的情况。
2)为key的过期时间加一个随机数
这种方案就是使每个key的过期时间尽量不一样,防止大量的key同时过期的情况。
3)使用缓存标记
给每一个缓存的key增加一个缓存标记,例如缓存key = "hotel_name",缓存标记的signKey = "hotel_name_sign",并且使缓存标记的过期时间小于缓存数据的过期时间。
在根据缓存key获取数据时,先获取该key的缓存标记是否存在,如果存在,则直接查询缓存并返回,如果缓存标记不存在,则表示缓存标记已经过期并且缓存即将过期,这时通过起个线程等异步方式去更新缓存key,并返回数据。
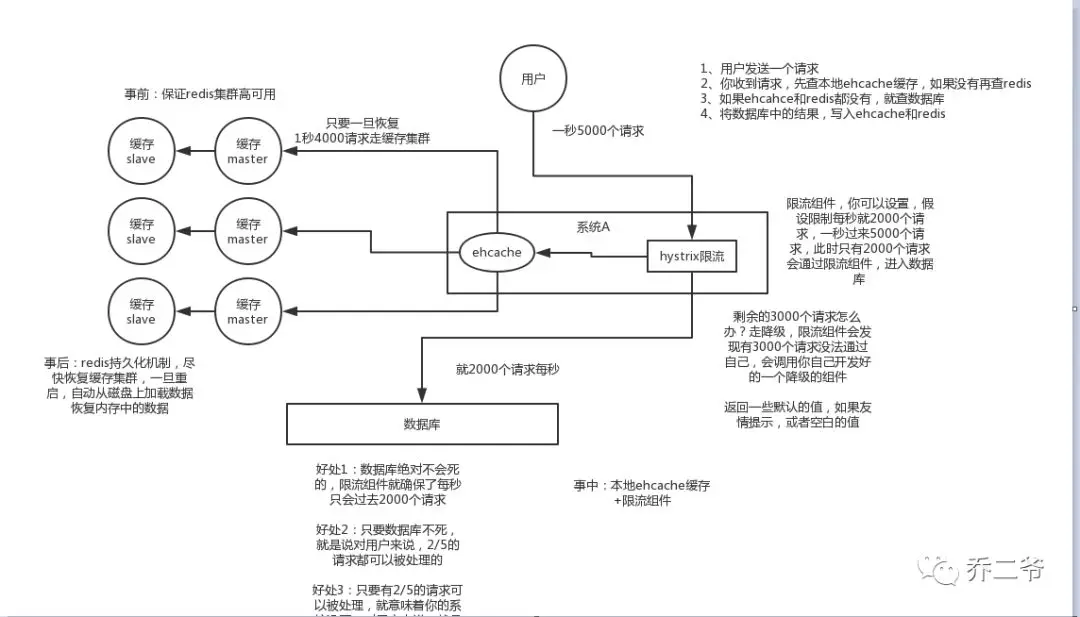
2、事中:
ehcache本地缓存 + Hystrix限流&降级,避免MySQL被打死
使用 ehcache 本地缓存的目的也是考虑在 Redis Cluster 完全不可用的时候,ehcache 本地缓存还能够支撑一阵。
使用 Hystrix进行限流 & 降级 ,比如一秒来了5000个请求,我们可以设置假设只能有一秒 2000个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑。
然后去调用我们自己开发的降级组件(降级),比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
3、事后:
开启Redis持久化机制,尽快恢复缓存集群
一旦重启,就能从磁盘上自动加载数据恢复内存中的数据。
防止缓存雪崩方案如下图:
4、解决热点数据集中失效问题
(1)我们在设置缓存的时候,一般会给缓存设置一个失效时间,过了这个时间,缓存就失效了。对于一些热点的数据来说,当缓存失效以后会存在大量的请求过来,然后打到数据库去,从而可能导致数据库崩溃的情况。
(2) 解决办法
1 设置不同的失效时间
为了避免这些热点的数据集中失效,那么我们在设置缓存过期时间的时候,我们让他们失效的时间错开。比如在一个基础的时间上加上或者减去一个范围内的随机值。
2 互斥锁
结合上面的击穿的情况,在第一个请求去查询数据库的时候对他加一个互斥锁,其余的查询请求都会被阻塞住,直到锁被释放,从而保护数据库。但是也是由于它会阻塞其他的线程,此时系统吞吐量会下降。需要结合实际的业务去考虑是否要这么做。
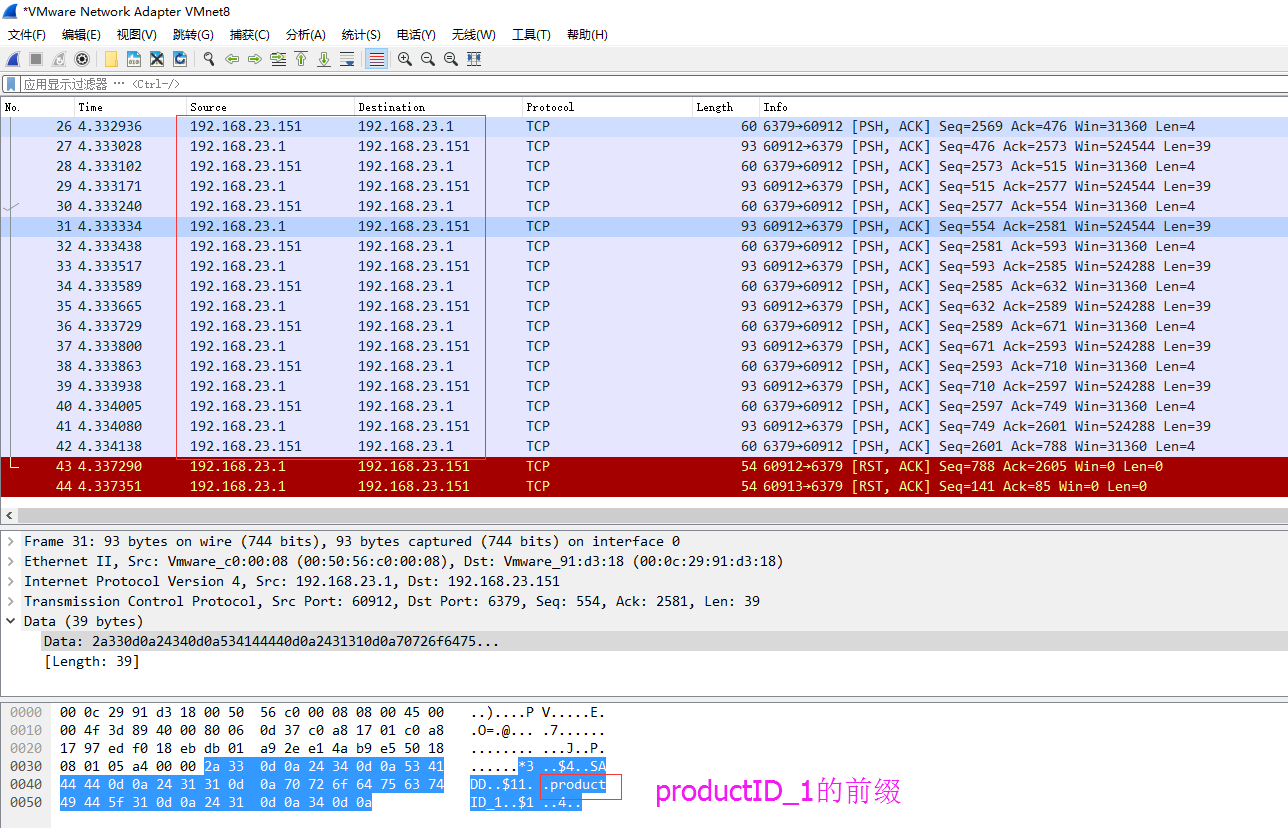
九 Redis如何快速删除1.2亿+指定前缀的key
此问题可以延伸为Redis如何访问海量的数据。有时候我们需要知道线上的Redis的使用情况,尤其需要知道一些前缀的key值,让我们怎么去查看呢?并且通常情况下Redis里的数据都是海量的,那么我们访问Redis中的海量数据?
1 事故产生原因
因为我们的用户token缓存是采用了【user_token:userid】格式的key,保存用户的token的值。我们运维为了帮助开发小伙伴们查一下线上现在有多少登录用户。
直接用了 keys user_token* 方式进行查询,事故就此发生了。导致Redis不可用,假死。
2 原因分析
我们线上的登录用户有几百万,数据量比较多;keys算法是遍历算法,复杂度是O(n),也就是数据越多,时间越高。
数据量达到几百万,keys这个指令就会导致 Redis 服务卡顿,因为 Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的 keys 指令执行完了才可以继续。
3 解决方案
那我们如何去遍历大数据量呢?这个也是面试经常问的。我们可以采用Redis的另一个命令scan。我们看一下scan的特点:
1. 复杂度虽然也是 O(n),但是它是通过游标分步进行的,不会阻塞线程。
2. 提供 count 参数,不是结果数量,而是Redis单次遍历字典槽位数量(约等于)。
3. 同 keys 一样,它也提供模式匹配功能;
4. 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
5. 返回的结果可能会有重复,需要客户端去重复,这点非常重要;
6. 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零
也就是说:SCAN 命令是一个基于游标的迭代器(cursor based iterator): SCAN 命令每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 以此来延续之前的迭代过程。当 SCAN 命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。 SCAN的语法如下 :
cousor 是游标,MATCH 则支持正则匹配,我们正好可以利用此功能,比如匹配 前缀为"dba_"的key, COUNT 是每次获取多少个key。
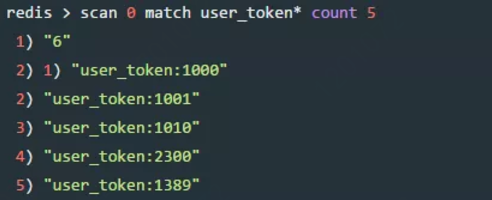
从0开始遍历,返回了游标6,又返回了数据,继续scan遍历,就要从6开始

从上面的示例可以看到, SCAN 命令的回复是一个包含两个元素的数组, 第一个数组元素是用于进行下一次迭代的新游标, 而第二个数组元素则是一个数组, 这个数组中包含了所有被迭代的元素。注意:以 0 作为游标开始一次新的迭代, 一直调用 SCAN 命令, 直到命令返回游标 0 , 我们称这个过程为一次完整遍历(full iteration)。
4 如何执行删除
Redis本身是基于Request/Response协议的,客户端发送一个命令,等待Redis应答,Redis在接收到命令,处理后应答。其中发送命令加上返回结果的时间称为(Round Time Trip)RRT-往返时间。
如果客户端发送大量的命令给Redis,那就是等待上一条命令应答后再执行再执行下一条命令,这中间不仅仅多了RTT,而且还频繁的调用系统IO,发送网络请求。
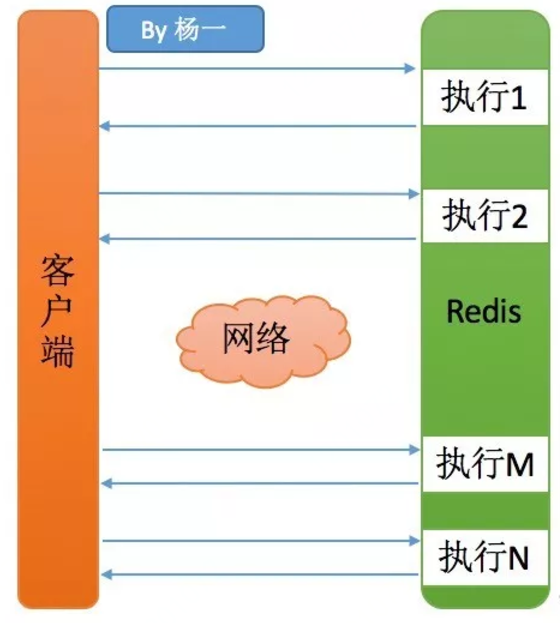
Pipeline(流水线)功能极大的改善了上面的缺点。Pipeline能将一组Redis命令进行组装,然后一次性传输给Redis,再将Redis执行这组命令的结果按照顺序返回给客户端。

需要注意的是Pipeline 虽然好用,但是Pipline组装的命令个数不能没有限制,否则一次组装数据量过大,一方面增加客户端的等待时间,另一方面会造成网络阻塞,需要批量组装。
参考:
1、Redis 基础、高级特性与性能调优 https://mp.weixin.qq.com/s/aCbRr5QFVuQJgFhkOaiZcA
2、关于【缓存穿透、缓存击穿、缓存雪崩、热点数据失效】问题的解决方案 https://mp.weixin.qq.com/s/5MloHIa5zKvYYsVVEWZjQA
4、Redis事务 https://redisbook.readthedocs.io/en/latest/feature/transaction.html https://www.cnblogs.com/kangoroo/p/7535405.html
- 上一篇: Redis基础与性能调优
- 下一篇: redis分布式锁原理与实现
相关文章
-
Redis基础与性能调优
Redis基础与性能调优
- 互联网
- 2026年06月03日
-
Redis介绍及常用命令
Redis介绍及常用命令
- 互联网
- 2026年06月03日
-
redis配置认证密码(转)
redis配置认证密码(转)
- 互联网
- 2026年06月03日
-
redis分布式锁原理与实现
redis分布式锁原理与实现
- 互联网
- 2026年06月03日
-
redis对外提供IP和端口
redis对外提供IP和端口
- 互联网
- 2026年06月03日
-
redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
- 互联网
- 2026年06月03日



