Excel百万数据如何快速导入?
- 作者: 五速梦信息网
- 时间: 2026年06月19日 04:39
metrics() {
return registry -> registry.config().meterFilter(
new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
return DistributionStatisticConfig.builder()
.percentiles(0.5, 0.95) // 统计中位数和95分位
.build().merge(config);
}
}
);
} “`
四、百万级导入性能实测对比
测试环境:
服务器:4核8G,MySQL 8.0
数据量:100万行x15列(约200MB Excel)
方案 内存峰值 耗时 吞吐量 传统逐条插入 2.5GB 96分钟 173条/秒 分页读取+批量插入 500MB 7分钟 2381条/秒 多线程分片+异步批量 800MB 86秒 11627条/秒 分布式分片(3节点) 300MB/节点 29秒 34482条/秒 总结
Excel高性能导入的11条军规:
- 决不允许全量加载数据到内存 → 使用SAX流式解析
- 避免逐行操作数据库 → 批量插入加持
- 永远不要让用户等待 → 异步处理+进度查询
- 横向扩展比纵向优化更有效 → 分片+分布式计算
- 内存管理是生死线 → 对象池+避免临时大对象
- 合理配置连接池参数 → 杜绝瓶颈在数据源
- 前置校验绝不动摇 → 脏数据必须拦截在入口
- 监控务必完善 → 掌握全链路指标
- 设计必须支持容灾 → 断点续传+幂等处理
- 抛弃单机思维 → 拥抱分布式系统设计
- 测试要覆盖极端场景 → 百万数据压测不可少 如果你正在为Excel导入性能苦恼,希望这篇文章能为你的系统打开一扇新的大门。
- 上一篇: Excel百万数据导出最佳实战指南
- 下一篇: Fabric.js 学习笔记,快速上手
相关文章
-
Excel百万数据导出最佳实战指南
Excel百万数据导出最佳实战指南
- 互联网
- 2026年06月19日
-

excelwps, 转code128字体宏, 部分字符串出现空格, 导致条码断裂无法扫描的解决方案
excelwps, 转code128字体宏, 部分字符串出现空格, 导致条码断裂无法扫描的解决方案
- 互联网
- 2026年06月19日
-
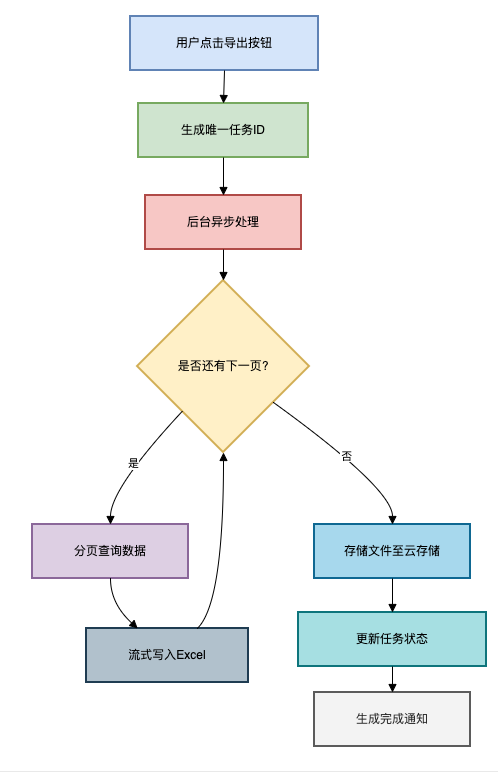
Excel 高性能导出方案推荐(JAVA)
Excel 高性能导出方案推荐(JAVA)
- 互联网
- 2026年06月19日
-
Fabric.js 学习笔记,快速上手
Fabric.js 学习笔记,快速上手
- 互联网
- 2026年06月19日
-
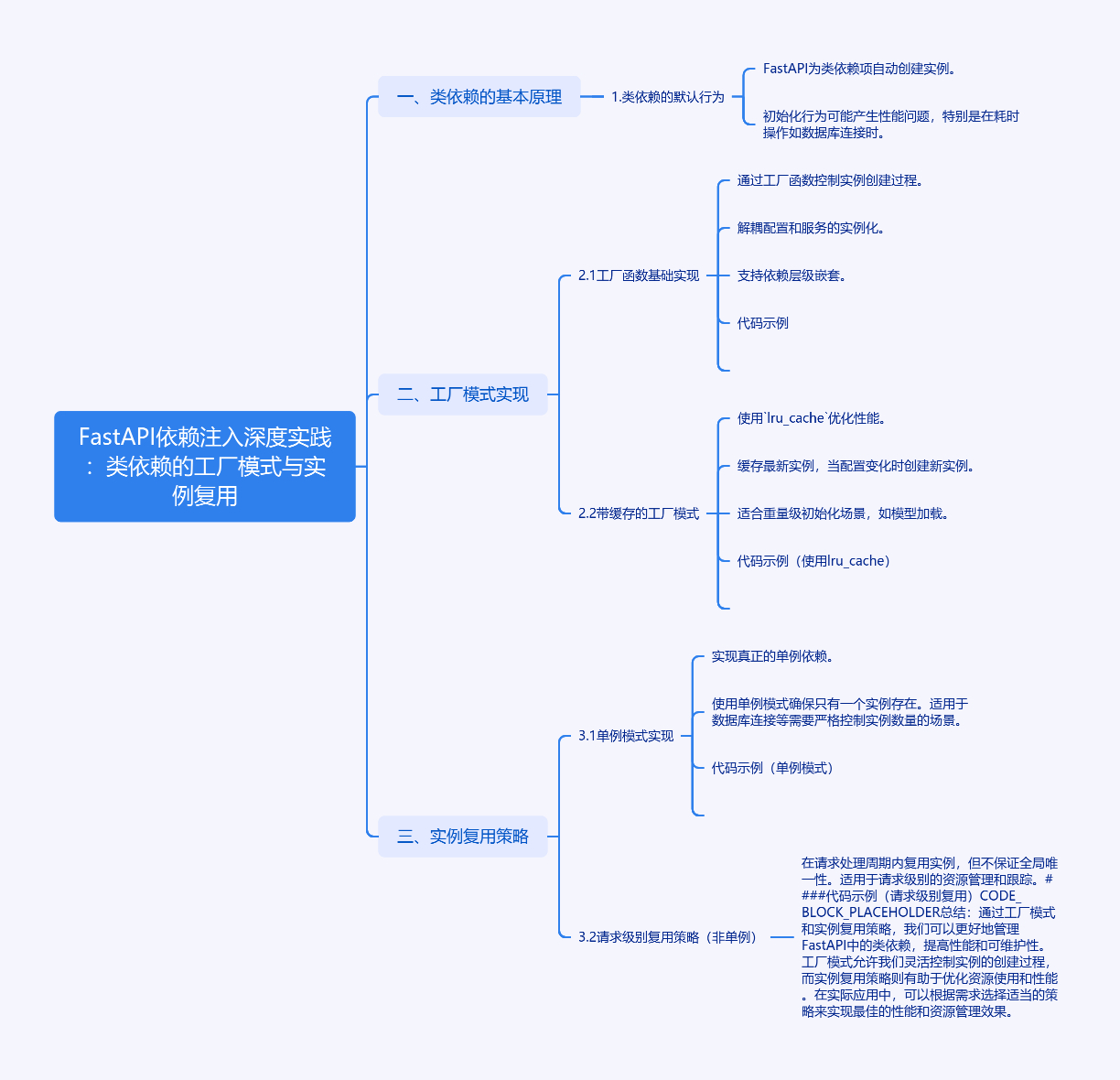
FastAPI依赖注入实践:工厂模式与实例复用的优化策略
FastAPI依赖注入实践:工厂模式与实例复用的优化策略
- 互联网
- 2026年06月19日
-
FastPrompt,一个快速高效的命令提示行工具推荐
FastPrompt,一个快速高效的命令提示行工具推荐
- 互联网
- 2026年06月19日